ĐỒ ÁN TỐT NGHIỆP ĐIỆN TỬ Nâng cao chất lượng tín hiệu tiếng nói sử dụng bộ lọc Kalman
NỘI DUNG ĐỒ ÁN
ĐỒ ÁN TỐT NGHIỆP ĐIỆN TỬ Nâng cao chất lượng tín hiệu tiếng nói sử dụng bộ lọc Kalman
DANH MỤC CÁC TỪ VIẾT TẮT
|
Từ viết tắt |
Tiếng Anh |
|
ACR |
Absolute Category Rating |
|
AR |
Autoregressive |
|
AWRN |
Add White Gaussian Noise |
|
CCR |
Comparition Category Rating |
|
DCR |
Degradation Category Rating |
|
LP |
Linear Prediction |
|
MA |
Moving Average |
|
MOS |
Mean Opinion Scoring |
|
SS |
Spectral Subtraction |
|
SNR |
Signal Noise Ratio |
MỤC LỤC
LỜI CAM ĐOAN.. 1
DANH MỤC CÁC TỪ VIẾT TẮT.. 2
MỤC LỤC.. 3
LỜI MỞ ĐẦU.. 6
CHƯƠNG 1: TÍN HIỆU TIẾNG NÓI7
1.1 Giới thiệu chương. 7
1.2 Tín hiệu tiếng nói7
1.2.1 Tín hiệu. 7
1.1.2 Tín hiệu tiếng nói8
1.1.3Biểu diễn tín hiệu tiếng nói8
1.1.3.1 Biểu diễn bằng dạng sóng theo thời gian. 8
1.1.3.2 Biểu diễn bằng phổ tín hiệu tiếng nói10
1.1.3.3 Biểu diễn bằng ảnh phổ. 10
1.2 Nâng cao chất lượng tiếng nói (Speech enhancement). 11
1.3 Mô hình tiếng nói14
1.3.1 Cơ chế sản xuất tiếng nói15
1.3.2 Phương pháp dự đoán tuyến tính (Linear prediction-LP). 17
1.4 Kết luận chương. 20
CHƯƠNG 2: BỘ LỌC KALMAN.. 21
2.1 Giới thiệu chương. 21
2.2 Lý thuyết về ước lượng. 21
2.2.1 Khái niệm.. 21
2.2.2 Đánh giá chất lượng. 21
2.2.3 Kỳ vọng (Expectation). 22
2.2.4 Phương sai (Variance). 23
2.2.5 Độ lệch chuẩn. 24
2.2.6 Hiệp phương sai (Covariance). 24
2.2.7 Ma trận hiệp phương sai25
2.2.8 Phân phối chuẩn (phân phối Gaussian). 26
2.2.9 Ước lượng của trung bình và phương sai28
2.2.10 Phương pháp bình phương tối thiểu. 29
2.3 Bộ lọc Kalman. 31
2.3.1 Giới thiệu chung về bộ lọc Kalman. 31
2.3.2 Mô hình toán học. 32
2.3.2.1 Hệ thống và mô hình quan sát32
2.3.2.2 Giả thiết33
2.3.2.3 Nguồn gốc. 34
2.3.2.4 Điều kiện không chệch. 36
2.3.2.5 Hiệp phương sai sai số. 38
2.3.2.6 Độ lời Kalman. 39
2.3.2.7 Tóm tắt các phương trình của bộ lọc Kalman. 40
2.4Ưu nhược điểm của bộ lọc Kalman. 42
2.4.1 Ưu điểm.. 42
2.4.2 Nhược điểm.. 43
2.5 Kết luận chương. 43
CHƯƠNG 3: ÁP DỤNG BỘ LỌC KALMAN ĐỂ NÂNG CAO CHẤT LƯỢNG TÍN HIỆU TIẾNG NÓI44
3.1 Giới thiệu chương. 44
3.2 Cơ sở dữ liệu và phương pháp đánh giá.44
3.2.1 Cơ sở dữ liệu.44
3.2.2 Phương pháp đánh giá MOS. 44
3.3 Mô phỏng và đánh giá kết quả. 46
3.3.1 Mô phỏng. 46
3.3.2 Đánh giá kết quả dựa trên phương pháp MOS. 53
3.4 Kết luận chương.55
KẾT LUẬN VÀ HƯỚNG PHÁT TRIỂN ĐỀ TÀI56
TÀI LIỆU THAM KHẢO.. 57
PHỤ LỤC.. 58
LỜI MỞ ĐẦU
Ngày nay,cùng với sự phát triển của khoa học kĩ thuật thì việc liên lạc trao đổi thông tin của con người trở nên dễ dàng hơn bao giờ hết. Đặc biệt, việc liên lạc qua điện thoại đã trở nên phổ biến, chúng ta có thể nói chuyện với bất kì ai ở bất cứ nơi đâu.Nhưng trong một số trường hợp, chất lương cuộc hội thoại không như ta mong muốn. Ví dụ như ta đứng ở nhà ga, bến tàu, trên đường phố hoặc những nơi đông người thì việc nói chuyện qua điện thoại gặp khá nhiều khó khăn do ảnh hưởng của những tiếng ồn xung quanh.
Vì vậy mục đích của đồ án này là: xử lý để loại bỏ tối đa tiếng ồn (nhiễu) xung quanh, giữ chất lượng tín hiệu tiếng nói mà ta muốn truyền đạt. Bộ lọc Kalman ( tên được đặt theo nhà nghiên cứu Rudolf (Rudy) E. Kálmán ) được chọn làm công cụ để giải quyết vấn đề trên. Để thực hiện mục đích nâng cao chất lượng tín hiệu tiếng nói sử dụng bộ lọc Kalman thì đồ án được cấu trúc theo các phần sau:
- Phần đầu, chúng ta sẽ tìm hiểu về tín hiệu tiếng nói cách hình thành tiếng nói và các mô hình phân tích tiếng nói, đặc biệt phần này sẽ đề cập đến việc nâng cao chất lượng tiếng nói cũng như các thuật toán được sử dụng hiện nay
- Bộ lọc Kalman, phần này sẽ cho chúng ta thấy rõ hơn về bộ lọc Kalman, thuật toán, các phương trình của bộ lọc đồng thời cũng nêu ra ưu điểm và nhược điểm khi sử dụng bộ lọc Kalman
- Phần cuối sẽ thực hiện giảm nhiễu trong các cuộc hội thoại bằng thuật toán của bộ lọc Kalman. Đồng thời phân tích đánh giá kết quả thông qua phương pháp MOS
CHƯƠNG 1: TÍN HIỆU TIẾNG NÓI
1.1 Giới thiệu chương
Nội dung của chương trình bày sơ lượt về tín hiệu tiếng nói, cách hình thành, mô hình phổ biến để biểu diễn, phân tích và xử lý tín hiệu tiếng nói.Bên cạnh đó, chương này còn khái quát mục đích của nâng cao chất lượng tiếng nói và các phương pháp sử dụng để nâng cao chất lượng tín hiệu tiếng nói hiện nay.
1.2 Tín hiệu tiếng nói
1.2.1Tín hiệu
Tín hiệu(signal) dùng để chỉ một đại lượng vật lý mang tin tức. Về mặt toán học, ta có thể mô tả tín hiệu như một hàm theo biến thời gian, không gian hay các biến độc lập khác. Chẳng hạn như, hàm: x(t) = 20t2 mô tả tín hiệu biến thiên theo biến thời gian t. Hay một ví dụ khác, hàm: s(x,y) = 3x + 5xy + y2 mô tả tín hiệu là hàm theo hai biến độc lập x và y, trong đó x và y biểu diễn cho hai tọa độ trong mặt phẳng .
Hai tín hiệu trong ví dụ trên về lớp tín hiệu được biểu diễn chính xác bằng hàm theobiến độc lập. Tuy nhiên, trong thực tế, các mối quan hệ giữa các đại lượng vật lý và các biến độc lập thường rất phức tạp nên không thể biểu diễn tín hiệu nhưtrong hai ví dụ vừa nêu trên.Lấy ví dụ tín hiệu tiếng nói - đó là sự biến thiên của áp suất không khí theothời gian. Chẳng hạn khi ta phát âm từ "away", dạng sóng của nó được biểu diễn như hình sau.
Hình 1.1 Dạng sóng khi phát âm từ “away”
1.1.2Tín hiệu tiếng nói
Mục đích của tiếng nói là truyền thông tin.Để xét quá trình thông tin tiếng nói, đầu tiên nên coi thông báo như một dạng trừu tượng nào đó trong óc người nói.Qua quá trình phức tạp tạo âm, thông tin trong thông báo này được chuyển trực tiếp thành tín hiệu âm học. Thông tin thông báo có thể được biểu diễn dưới một số dạng khác nhau trong quá trình tạo tiếng nói. Chẳng hạn, thông tin thông báo lúc ban đầu đƣợc chuyển thành tập hợp các tín hiệu thần kinh điều khiển cơ chế phát âm (đó là chuyển động của lưỡi, môi, dây thanh âm, v. v...). Bộ máy phát âm chuyển động tương ứng với các tín hiệu thần kinh này để tạo ra dãy các điệu bộ, mà kết quả cuối cùng là dạng sóng âm chứa thông tin trong thông báo gốc.
Tín hiệu tiếng nói thường được thể hiện dưới dạng số, tức là được "số hóa", và do đó xử lý tiếng nói có thể được coi là giao của xử lý tín hiệu số vàxử lý ngôn ngữ tự nhiên.
1.1.3Biểu diễn tín hiệu tiếng nói
1.1.3.1 Biểu diễn bằng dạng sóng theo thời gian
Phần tín hiệu ứng với âm vô thanh là không tuần hoàn, ngẫu nhiên và có biên độ hay năng lượng nhỏ hơn của nguyên âm.Ranh giới giữa các từ là các khoảng lặng(Silent). Ta cần phân biệt rõ các khoảng lặng với âm vô thanh.
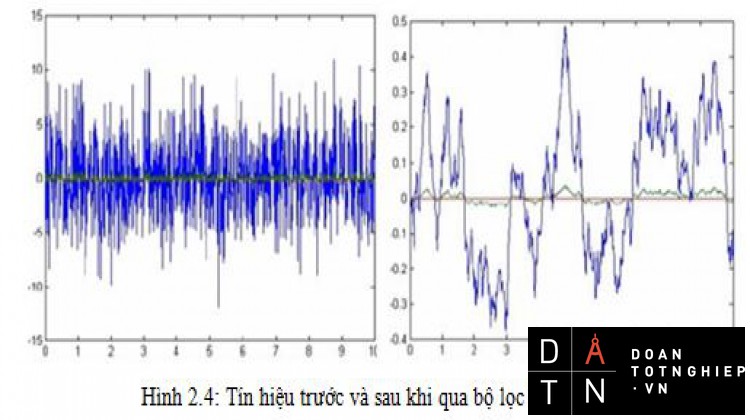
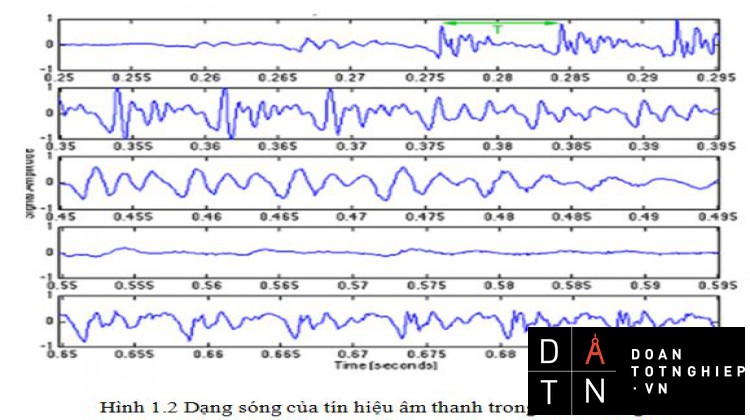
Hình 1.2 Dạng sóng của tín hiệu âm thanh trong miền thời gian
Âm thanh được lưu trữ theo định dạng thông dụng trong máy tính là *.WAV với các tần số lấy mẫu thường gặp là: 8000Hz, 10000Hz, 11025Hz, 16000Hz, 22050Hz, 32000Hz, 44100Hz. Độ phân giải hay còn gọi là số bít trên mỗi mẫu là 8 hoặc 16 bít và sô kênh là 1 (Mono) hoặc 2 (Stereo).
Như vậy, dữ liệu lưa trữ của tín hiệu âm thanh sẽ khác nhau tuỳ theo máy thu thanh, thời điểm phát âm hay người phát âm, điều này được thể hiện rõ nét trong các hình vẽ sau:
Hình 1.3: Tín hiệu tiếng nói thu từ hai micro khác nhau
1.1.3.2Biểu diễn bằng phổ tín hiệu tiếng nói
Dải tần số của tín hiệu âm thanh nằm trong khoảng tần số từ 0Hz đến 20KHz, tuy nhiên phần lớn công suất nằm trong dải tần số từ 0,3KHz đến 3,4KHz
Hình 1.4: Dạng sóng và công suất phổ tín hiệu tiếng nói theo thời gian
1.1.3.3Biểu diễn bằng ảnh phổ
Để biểu diễn ảnh phổ(spectrogram) của tín hiệu ta tiến hành chia tín hiệu thành các khung(frame) ứng với độ dài cửa sổ thông thường khoảng 10ms.Tín hiệu trên các khung đuợc lấy mẫu với tần số lấy mẫu Fs, nếu tần số lấy mẫu là 16000Hz thì ta sẽ có được 16 mẫucho 1ms và có được 160 mẫu cho một khung. Các khung này được chọn theo hai hàm cửa sổ thông dụng là hamming hoặc hanning có độ chồng lấn hai biên khoảng 40%(4ms).
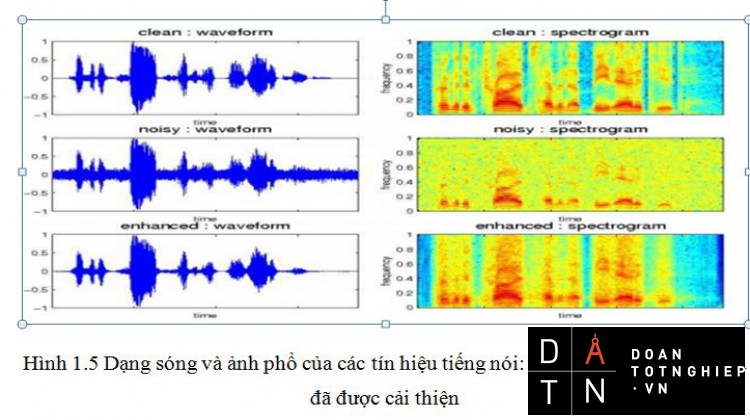
Hình 1.5 Dạng sóng và ảnh phổ của các tín hiệu tiếng nói: sạch, bị nhiễu và tín hiệu đã được cải thiện
Ảnh phổ được tạo bằng cách vẽ phổ của các khung tín hiệu trên trục thẳng đứng, trong spectrogram thì thời gian và tần số tương ứng với các trục ngang và dọc, còn biên độ phổ được biểu diễn bằng độ đậm nhạc của màu sắc, ảnh phổ là kết quả ghép nối của các khung phổ.
1.2Nâng cao chất lượng tiếng nói (Speech enhancement)
Nâng cao chất lượng tiếng nói liên quan đến việc cải thiện cảm nhận đối với tiếng nói bị suy giảm chất lượng do sự có mặt của nhiễu trong tiếng nói. Trong hầu hết các ứng dụng, thì mục đích của nâng cao chất lượng tiếng nói là sự cải thiện chất lượng và tính dễ nghe của tiếng nói đã bị suy giảm do nhiễu bằng cách sử dụng các công cụ xử lý tín hiệu.
Có rất nhiều yêu cầu đặt ra đối với Speech enhancement trong nhiều trường hợp khác nhau, ví dụ đối với thông tin thoại, trên các hệ thống điện thoại tế bào thì chịu sự ảnh hưởng nhiễu nền từ ô tô, nhà hàng,.. khi truyền đến đích. Chính vì vậy mà các thuật toán trong nâng cao chất lượng tiếng nói có thể được sử dụng để cải thiện chất lượng của tiếng nói tại điểm thu, mặt khác, nó có thể được sử dụng trong các khối tiền xử lý của hệ thống mã hoá tiếng nói dùng trong các điện thoại tế bào chuẩn. Khi nhận dạng tiếng nói, tiếng nói bị nhiễu được tiền xử lý bởi các thuật toán nâng cao chất lượng trước khi được nhận dạng.Trong thông tin liên lạc hàng không, các kỹ thuật nâng cao tiếng nói cần được sử dụng để cải thiện chất lượng và tính dễ nghe của tiếng nói của phi công bị ảnh hưởng bởi nhiễu trong buồng lái.Vìvậy mà việc nâng cao chất lượng tiếng nói cũng rất cần thiết trong thông tin liên lạc quân sự.
Speech enhancementlà một phần của xử lý tiếng nói mà mục đích là cải thiện tính dễ nghe của tín hiệu tiếng nói.Cách tiếp cận phổ biến nhất trong Speech enhancement là loại bỏ nhiễu, bằng cách dự đoán các đặt điểm của nhiễu, sau đó loại bỏ thành phần nhiễu chỉ giữ lại tín hiệu sạch. Nhưng vấn đề cơ bản của phương pháp này là nếu trong tín hiệu có những thành phần có đặt điểm tương tự nhiễu nhưng lại là thành phần hữu ích thì khi ta loại bỏ nhiễu, vô hình chung ta cũng loại bỏ những thành phần đó và làm méo dạng tín hiệu. Do đó, các phương pháp Speech enhancement phải cân bằng giữa việc loại bỏ nhiễu và mức độ biến dạng của tín hiệu tiếng nói.
Thông thường các thuật toán xử lý tiếng nói có thể chia làm ba loại chính: Thuật toán trừ phổ (spectral subtraction), phép phân tích không gian con (sub-space analysis) và các thuật toán lọc (filtering algorithms):
- Spectral subtraction (SS): hay còn gọi là trừ phổ là một thuật toán giảm nhiễu đơn giản nhất. Nó dựa trên nguyên lý cơ bản là nó sẽ mô tả và cập nhật nhiễu trong tín hiệu có nhiễu bằng cách thu nhiễu khi không có sự hiện diện của tín hiệu. Và nhiễu đó sẽ được trừ với tín hiệu có nhiễu, kết quả là tín hiệu của chúng ta sau khi xử lý bằng thuật toán này sẽ được loại đi nhiễu và xét trên phương diện lý tưởng thì nó là tín hiệu sạch. SS lúc ban đầu được đề xuất bởi Weiss trong miền tương quan, và sau đó được đề xuất bởi Boll trong miền chuyển đổi Fourier.
- Sub-space analysis :Thuật toán này dựa trên lý thuyết số học tuyến tính và hoạt động dựa trên nguyên tắc tín hiệu sạch phải được đưa vào một không gian con của không gian nhiễu Euclidean. Sau đó, người ta đưa ra một phương pháp để phân rã không gian vector của tín hiệu nhiễu thành hai không gian con khác nhau gồm một không gian con được chiếm dụng bởi tin hiệu sạch và một không gian con được chiếm dụng bởi nhiễu. Thuật toán này ban đầu được xây dựng bởi Dendrinos và sau này được phát triển bởi Ephraim và Van Trees.
- Filtering algorithms : Các thuật toán lọc là các phương pháp sử dụng trong miền thời gian mà mục đích là cố gắng loại bỏ thành phần nhiễu (Wiener filtering) hay ước lượng nhiễu và thành phần tiếng nói gần như là bộ lọc (Kalman filtering).
Có một thuật toán quan trọng để nâng cao chất lượng tiếng nói thuộc nhóm các phương pháp tham số mà tín hiệu tiếng nói được mô hình hóa như một quá trình tự hồi qui (autoregressive) được gắn trong nhiễu Gaussian.
Thuật toán nâng cao chất lượng tiếng nói loại này gồm hai bước :
- Ước tính các hệ số AR (Autoregressive) và phương sai nhiễu(sử dụng phương pháp dự đoán tuyến tính)
- Áp dụng bộ lọc Kalman bằng cách sử dụng các thông số đã ước tính để dự đoán tín hiệu sạch từ tín mẫu tín hiệu bị nhiễu.
1.3Mô hình tiếng nói
Các mô hình nghiên cứu tiếng nói cho chúng ta thấy cách thức con người tạo ra tiếng nói. Ngày nay, có rất nhiều thiết bị tương tác với chúng ta qua ngôn ngữ của con người, và âm thanh chúng phát ra càng giống với con người càng tốt. Do đó, nhiều công trình nghiên cứu ra đời với mục đích tìm ra mô hình tốt nhất mô tả cơ chế phát ra tiếng nói (hình 1.6)
Hình 1.6: Mô hình phát ra tiếng nói
Đầu tiên, với mô hình này chúng ta có thể quyết định được âm thanh phát ra là vô thanh hay hữu thanh. Đối với âm hữu thanh, chúng ta có mô hình phát xung thanh hầu tương tự như phát trong thanh quản.Đối với âm vô thanh, tín hiệu được phát ra giống như tiếng ồn, tương như tín hiệu mà ta có thể thấy trong các phụ âm.
Sau đó, tín hiệu phát ra đi qua đường âm thanh (vocal tract). Ở phần này, chúng ta lọc tín hiệu với bộ lọc mà cố gắng để mô phỏng theo hiệu ứng hình học của âm thanh trong khoang mũi, khoang họng. Cuối cùng là mô hình phát xạ không khí ra khỏi miệng tạo thành tiếng nói.
1.3.1Cơ chế sản xuất tiếng nói
Các thành phần chính trong hệ thống tạo tiếng nói (hình 1.7) là phổi, khí quản, dây thanh quản, khoang họng, khoang miệng và khoang mũi.
Khi chúng ta hít thở, không khí đi vào phổi sau đó được đẩy ra khí quản làm dây thanh quản rung động.Không khí gần như điều chế thành các xung tuần hoàn với một tần số nào đó khi chúng đi qua cổ họng, khoang miệng hoặc mũi. Tùy thuộc vào vị trí của lưỡi, hàm, răng, môi mà chúng ta tạo thành các âm thanh khác nhau.
Hình 1.7: Các bộ phận tao tiếng nói
Hình 1.8: Mô hình đơn giản của việc tạo tiếng nói
Con người sử dụng ngôn ngữ gần như vô thức mà không cần chú ý đến việc làm thế nào để nảo xử lý những thông tin. Có một số lượng lớn các cơ quan tham gia vào quá trình này.Lời nói xuất phát từ suy nghĩ, ý định giao tiếp trong não.Não kích các cơ hoạt động và phát ra tiếng nói.Người nghenhận âm thanh thông qua thính giác, chuyển âm thanh thành tín hiệu thần kinh mà não có thể hiểu được. Người nói liên tục giám sát và điều khiển các cơ quan tạo tiếng nói bằng cách nhận lại chính âm thanh của họ như một tín hiệu phản hồi.
Hình 1.9: Mô hình phát, thu tiếng nói
1.3.2Phương pháp dự đoán tuyến tính (Linear prediction-LP)
Phương pháp này mang lại ưu thế vượt trội cho việc ước lượng các thông số cơ bản của tiếng nói như độ cao, phổ… và mã hóa bit thấp để truyền dẫn và lưu trữ. Điều quan trọng của phương pháp này là khả năng ước lượng các thông số một cách chính xác và mối liên hệ trong việc tính toán tín hiệu tiếng nói.
Ý tưởng cơ bản của việc phân tích dự đoán tuyến tính là một mẫu tín hiệu tiếng nói có thể xấp xỉ với một mẫu trước đó.Bằng việc tối thiểu hóa tổng bình phương sai số giữu mẫu thực và mẫu dự đoán, các hệ số dự đoán sẽ quyết định việc tối thiểu hóa này.yn là tín hiệu đầu ra của một hệ thống xem như chưa biết tín hiệu đầu vào xn với quan hệ :
G là tham số của hệ thống giả định. Từ phương trình (1.1) ta có thể thấy yn là tổ hợp tuyến tính của những mẫu trước đó tại đầu ra và những mẫu hiện tại và quá khứ của tín hiệu đầu vào xn . Và có thể nhận thấy yn có thể được dự đoán từ tổ hợp tuyến tính của quá khứ và hiện tại của đầu ra và đầu vào.
Thực hiện biến đổi Z phương trình (1.1). Nếu H(z) là hàm truyền đạt của hệ thống thì:
Có hai mô hình đặc biệt:
- Mô hình toàn không : ak =0; 1 k p => còn gọi là mô hình trung bình động (moving average-MA)
- Mô hình toàn cực : bl= 0; 1 l q => còn gọi là mô hình tự hồi qui (autoregressive-AR)
Nếu coi hệ số p ở (1.1) là đủ lớn thì mô hình toàn cực là phương pháp mô hình rất tốt cho tín hiệu tiếng nói. Ưu điểm là G và ak có thể ước lượng và tính toán không mấy phức tạp. Việc ước lượng các thông số của mô hình có thể được thực hiện trong miền thời gian và tần số.Một bộ dự báo tuyến tính với hệ số ak được định nghĩa mà đầu ra của nó có phương trình:
Với ak là hệ số dự đoán, p là bậc của hệ thống và dấu trừ để tiện cho việc tính toán. Sai số dự đoán được định nghĩa là e(n):
Trong đó yn là tín hiệu gốc, a0=1. Vấn đề đặt ra là làm sao cho sai số dự đoán nhỏ là nhỏ nhất, gần tiến đến không (giá trị này thể hiện chất lượng bộ dự đoán). Nếu chúng ta biểu thị tổng bình phương lỗi bằng E thì:
Để E nhỏ nhất thì :
Để ước lượng được tối ưu thì ta tìm các giá trị ai sao cho E đạt cực tiểu. Có nhiều đề xuất cho giải thuật tìm các hệ số ai như phương pháp tự tương quan, phương pháp đồng phương sai… tuy nhiên phương pháp tự tương quan với giải thuật Durbin hay được dùng hơn cả và nó phù hợp viết chương trình cho vi xử lý.
Với
là hàm tự tương quan của yn . Do đó ta có thể nhận xét R(-i) =R(i).
Các hệ số R(i-k) tạo thành ma trận tự tương quan hay ma trận đối xứng có dạng:
1.4Kết luận chương
Chương này đã trình bày mục đích của nâng cao chất lượng tiếng nói là loại bỏ đến mức thấp nhất các thành phần nhiễu trong tín hiệu tiếng nói đã bị nhiễu bằng các phương pháp như: thuật toán trừ phổ (spectral subtraction), phép phân tích không gian con (sub-space analysis) hay các thuật toán lọc (filtering algorithms) .Ngoài ra chương này cũng cho ta thấy được mô hình phân tích tiếng nói và cơ chế tạo tiếng nói, đồng thời cũng giới thiệu sơ lượt về phương pháp dự đoán tuyến tính.
CHƯƠNG 2: BỘ LỌC KALMAN
2.1 Giới thiệu chương
Năm 1960 R.E. Kalman xuất bản một bài báo nổi tiếng mô tả về một giải pháp đệ quy để giải quyết vấn đề bộ lọc tuyến tính dữ liệu rời rạc. Kể từ đó, do có những ưu điểm lớn trong tính toán, bộ lọc Kalman là một chủ đề nhận được ngày càng nhiều nghiên cứu và ứng dụng, đặc biệt trong các hệ thống định vị, dẫn đường.
Bộ lọc Kalman là một tập hợp các phương trình toán học nhằm cung cấp một phương pháp tính toán hồi quy hiệu quả để ước lượng trạng thái của một quá trình, theo cách tối thiểu hóa giá trị trung bình của bình phương độ lỗi (phương sai: mean squared error). Bộ lọc rất hiệu quả trên các khía cạnh sau: Nó cho phép ước lượng trạng thái quá khứ, hiện tại thậm chí cả tương lai, và bộ lọc có thể hoạt động ngay cả khi độ chính xác thực sự của mô hình hệ thống là chưa biết.
Chương này sẽ trình bày sơ lượt về lý thuyết ước lượng, mô hình toán học của bộ lọc Kalman cũng như những ưu điểm và nhược điểm của bộ lọc này.
2.2 Lý thuyết về ước lượng
2.2.1 Khái niệm
Trong thống kê, một ước lượng là một giá trị được tính toán từ một mẫu thử và
người ta hy vọng đó là giá trị tiêu biểu cho giá trị cần xác định trong tập hợp. Người ta luôn tìm một ước lượng sao cho đó là ước lượng "không chệch", hội tụ, hiệu quả và vững(robust)..
Ví dụ muốn xác định độ cao trung bình của trẻ ở độ tuổi 10, ta thực hiện một điều tra trên một mẫu được lấy trên tập thể các trẻ em ở độ tuổi 10 (ví dụ mẫu điều tra là các em học sinh được lấy ngẫu nhiên từ nhiều trường ở nhiều vùng khác nhau).Chiều cao trung bình tính được từ mẫu điều tra này, thường là trung bình tích lũy, sẽ là một ước lượng cho chiều cao trung bình của trẻ em ở độ tuổi 10.
2.2.2 Đánh giá chất lượng
Một ước lượng là một giá trị x được tính toán trên một mẫu được lấy một cách
ngẫu nhiên, do đó giá trị của x là một biến ngẫu nhiên với kì vọng E(x) và phương sai V(x). Nghĩa là giá trị x có thể dao động tùy theo mẫu thử, nó có ít cơ hội để có thể bằng đúng chính xác giá trị X mà nó đang ước lượng. Mục đích ở đây là ta muốn có thể kiểm soát sựsai lệch giữa giá trị x và giá trị X.
Một biến ngẫu nhiên luôn dao động xung quanh giá trị kì vọng của nó. Ta muốn là kì vọng của x phải bằng X. Khi đó ta nói ước lượng là không chệch(unbiased).
Ta cũng muốn là khi mẫu thử càng rộng, thì sai lệch giữa x và X càng nhỏ. Khi đó ta nói ước lượng là hội tụ(converge). Định nghĩa theo ngôn ngữ toán học là như sau: (xn) hội tụ nếu với mọi số thực dương (xác suất để sai lệch với giá trị thực cần ước lượng lớn hơn tiến về 0 khi kích cỡ của mẫu thử càng lớn)
Biến ngẫu nhiên dao động quanh giá trị kì vọng của nó. Nếu phương sai V(x) càng bé, thì sự dao động càng yếu. Vì vậy ta muốn phương sai của ước lượng là nhỏ nhất có thể.Khi đó ta nói ước lượng là hiệu quả (eficient).
Cuối cùng, trong quá trình điều tra, có thể xuất hiện một giá trị "bất thường" (ví dụ có trẻ 10 tuổi nhưng cao 1,80 m). Ta muốn giá trị bất thường này không ảnh hưởng quá nhiều đến giá trị ước lượng. Khi đó ta nói ước lượng là vững (robust).Có thể thấy trung bình tích lũy trong ví dụ về chiều cao trung bình trẻ 10 tuổi không phải là một ước lượng vững.
2.2.3 Kỳ vọng (Expectation)
Định nghĩa: Giả sử