ĐỒ ÁN TỐT NGHIỆP ĐIỆN TỬ TIN HỌC NHẬN DẠNG KÍ TỰ IN HOA TIẾNG VIỆT
NỘI DUNG ĐỒ ÁN
TÓM TẮT NỘI DUNG ĐỒ ÁN:
NHẬN DẠNG KÍ TỰ IN HOA TIẾNG VIỆT
Giới thiệu:
Nhận dạng chữ in nói chung và nhận dạng chữ in tiếng Việt nói riêng đã và đang là bài toán thu hút được nhiều sự quan tâm và nghiên cứu. Vì vậy đồ án này em xin tìm hiểu một phần trong mảng này.
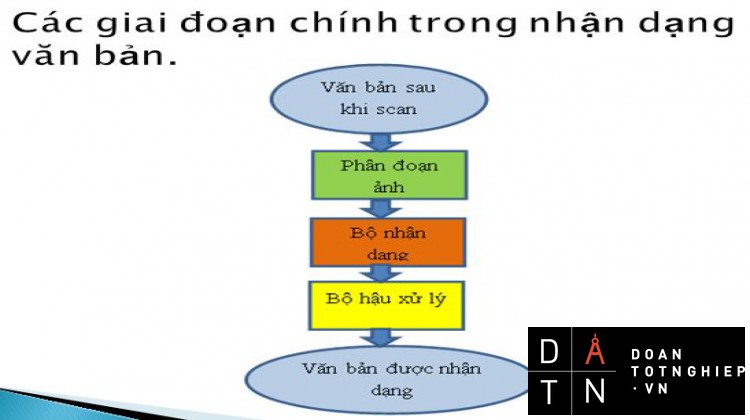
Bài toán nhận dạng chữ in Tiếng Việt gồm ba công đoạn chủ yếu: Phân đoạn ảnh thành các kí tự, Nhận dạng kí tự và hậu xử lý.
Với bài toán nhận dạng chữ in tiếng Việt có sự khó khăn do hệ thống có dấu mũ của các kí tự, làm tăng số kí tự cần nhận dạng, cũng như khó khăn trong việc nhận dạng kí tự vì các kí tự có đặc điểm khá giống nhau, đồng thời tăng khả năng giao nhau giữa các dòng. Để giải quyết vấn đề này, trong đồ án này, tôi sử dụng phương pháp tách dòng dựa vào khoảng trắng.
Đồ án gồm có 5 chương với bố cục như sau:
- Chương 1: Giới thiệu.
- Chương 2: Cơ sở lý thuyết cho phân đoạn ảnh và thuật toán nhận dạng kí tự.
- Chương 3: Phân đoạn ảnh cho nhận dạng kí tự.
- Chương 4: Bộ nhận dạng kí tự
- Chương 5: Thực nghiệm.
Chương 1: GIỚI THIỆU
Giới thiệu về nhận dạng kí tự quang học (ORC-Optical Character Recognition), các đặc điểm, khó khăn của nhận dạng kí tự. Giới thiệu một số hệ nhận dạng văn bản đã và đang được áp dụng trong thực tế. Giới thiệu các ứng dụng của nhận dạng kí tự quang học vào thực tế.
Hình 1 Sơ đồ khối hệ nhận dạng văn bản Tiếng Việt.
Chương 2: CƠ SỞ LÝ THUYẾT CHO PHÂN ĐOẠN ẢNH VÀ THUẬT TOÁN NHẬN DẠNG KÍ TỰ
Trong chương này, đồ án đề cập đến các vấn đề cơ bản về ảnh và xử lý ảnh cho bộ phân đoạn ảnh; đồng thời giới thiệu thuật toán nhận dạng cho bộ nhận dạng kí tự. Nội dung chương gồm các phần chính sau:
- Không gian màu RGB.
- Cơ bản về xử lý ảnh.
- Cơ sở lý thuyết cho phân đoạn ảnh.
- Phương pháp nhận dạng kí tự.
- Cơ sở lý thuyết của Kĩ thuật PCA.
Chương 3: PHÂN ĐOẠN ẢNH CHO NHẬN DẠNG VĂN BẢN.
Trong chương này, đồ án đề cập đến các quá trình phân đoạn ảnh cho nhận dạng văn bản. Các ảnh cần nhận dạng sẽ đi qua tuần tự các bước sau của bộ phân đoạn ảnh:
- Tiền xử lý ảnh.
- Các bức ảnh cần nhận dạng kí tự được thu thập bằng máy scanner.
- Sau đó xử lý nhiễu đễ nâng cao chất lượng ảnh.
- Ảnh sau khi lọc nhiễu sẽ được nhị phân hóa.
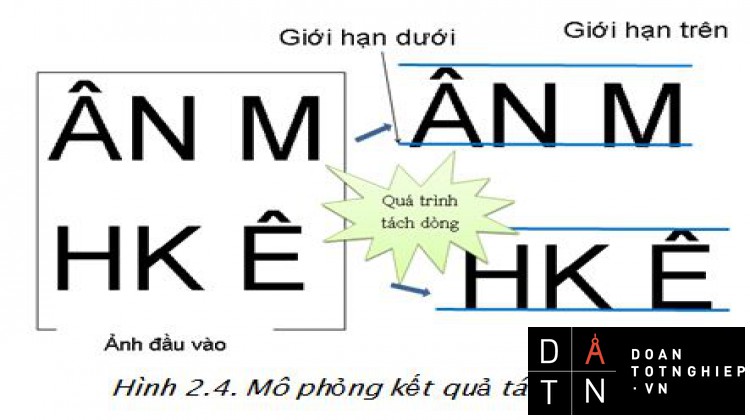
- Tách dòng.
- Ý tưởng chính là tách dòng dựa vào khoảng trắng giữa các dòng.
- Thuật toán: (Màu trắng tương ứng bit 1, đen tương ứng bit 0)
Bước 1:ghi lại các dòng có tất cả các bit 1 vào mảng C[].
Bước 2: Xét C[], nếu C(i+1)-C(i)≠1 thì lưu C(i) vào top1[], lưu C(i+1) vào bottom1[].
Bước 3: Ta cần phải có thuật toán để cắt chính xác các hàng kể cả dấu mũ.
Từ top1[] và bottom1[] ta tính giá trị tất cả các khoảng trắng trong văn bản bằng phương trình: bottom1(i+1)-top(i) = ti. Ta thu được tập T={t1, t2,…tn}.
Tính giá trị trung bình các khoảng trắng trong văn bản. T =
Bước 4: Nếu ti>T thì ta xác định được 1 vết cắt tại khoảng trắng này.
Tiếp tục cho đến hết ta sẽ xác định được tất cả các dòng.
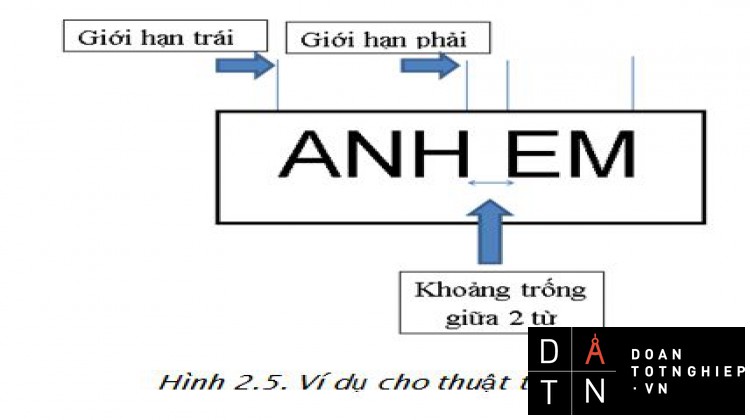
- Tách từ.
- Thuật toán:
Bước 1: Ta quét dòng từ đầu đến cuối và xác định tất cả các khoảng trống giữa các kí tự và lưu vào mảng.
Bước 2: Tính giá trị trung bình của các khoảng trống vừa tìm được.
Bước 3: Quét mảng khoảng trống, tại mỗi vị trí ta so sánh kích thước khoảng trống tại đó với giá trị trung bình các khoảng trống, nếu lớn hơn thì ta xác định được vị trí của vết cắt.
Bước 4: Tiếp tục cho đến hết dòng ta sẽ xác định được tất cả vị trí cắt.
Bước 5: Tiến hành tách từ dựa vào các vị trí cắt và đưa vào tách kí tự.
- Tách kí tự.
Thuật toán tìm vị trí cắt được thực hiện như sau:
Bước 1: Ta quét ảnh của 1 từ, xác định vị trí bắt đầu và kết thúc của các khoảng trắng.
Bước 2:Ta tiến hành cắt kí tự.
- Với kí tự đầu tiên: kí tự đầu tiên sẽ nằm giữa cột đầu tiên và vị trí bắt đầu của khoảng trắng đầu tiền. Như vậy vị trí cắt sẽ là cột đầu tiên và điểm bắt đầu của khoảng trắng đầu tiên.
- Với kí tự thứ 2: kí tự thứ 2 sẽ nằm giữa vị trí kết thúc của khoảng trắng đầu tiên và vị trí bắt đầu của khoảng trắng thứ 2.
- Tương tự với các kí tự tiếp theo.
Chương 4:BỘ NHẬN DẠNG KÍ TỰ.
Chương này nhằm đi sâu vào giới thiệu, tìm hiểu, phân tích thuật toán được sử dụng trong bộ nhận dạng kí tự cũng như nắm rõ cụ thể thuật toán PCA được sử dụng cụ thể cho nhận dạng kí tự như thế nào.
Chương này gồm các phần như sau:
- Ưu nhược điểm của thuật toán PCA.
- Thuật toán PCA cho nhận dạng kí tự.
- Kết luận chương.
Đồ án này sẽ tiến hành nhận dạng kí tự in hoa tiếng Việt. Như chúng ta đều biết kí tự in hoa tiếng Việt gồm có 29 kí tự như sau: A, Ă, Â, B, C, D, Đ, E, Ê, G, H, I, K, L, M, N, O, Ô, Ơ, P, Q, R, S, T, U, Ư, V, X, Y.
Hình 2. Các bước chính thực hiện PCA.
Chương 5: THỰC NGHIỆM ĐÁNH GIÁ KẾT QUẢ CHƯƠNG TRÌNH NHẬN DẠNG KÍ TỰ CHỮ IN HOA TIẾNG VIỆT.
Chương này chúng ta sẽ chạy mô phỏng và đánh giá hoạt động của bộ nhận dạng kí tự đồng thời đánh giá kết quả nhận dạng văn bản.
Nội dung của chương này bao gồm các phần sau:
- Kết quả thực nghiệm, nhận xét và đánh giá bộ phân đoạn ảnh.
- Kết quả thực nghiệm, nhận xét và đánh giá bộ nhận dạng kí tự.
- Kết quả thực nghiệm, nhận xét và đánh giá chương trình nhận dạng văn bản.
- Nhận xét, đánh giá quá trình thực hiện.
- Điều kiện thực nghiệm:Tôi thực nghiệm phân tách 10 văn bản gồm 100 dòng 742 từ, trong mỗi văn bản các dòng có cùng kích thước chữ.
- Kết quả thực nghiệm:
- Quá trình tách dòng cho kết quả chính xác 98%.
- Quá trình tách từ cho kết quả chính xác 96,63%.
- Quá trình tách kí tự và nhận dạng cho kết quả chính xác 95,56%.
Kết luận
Nhận dạng kí tự in hoa Tiếng Việt là nhận dạng 29 kí tự in hoa Tiếng Việt gồm: A, Ă, Â, B, C, D, Đ, E, Ê, G, H, I, K, L, M, N, O, Ô, Ơ, P, Q, R, S, T, U, Ư, V, X, Y. Qua thực nghiệm, nhận thấy các kí tự Q và O, C và O, R và P thường bị nhầm lẫn với nhau, ngoài ra các kí tự khác có độ chính xác khá cao.
Chương trình test có thời gian đáp ứng khá nhanh, kết quả nhận được có độ chính xác trên 90%. Hệ thống còn một số hạn chế về tách từ và tách kí tự gián tiếp làm giảm khả năng nhận dạng của hệ thống. Cần áp dụng các kĩ thuật tốt hơn để làm tăng khả năng tách từ và tách kí tự, như vậy có thể tăng độ chính xác lên hơn 90% như bây giờ.
Trong tương lai, tôi sẽ tiếp tục nghiên cứu và phát triển để nâng cao chất lượng hệ thống cả về độ chính xác và tốc độ; có thể cải thiện quá trình tách kí tự để đạt độ chính xác hơn. Từng bước nghiên cứ và xây dựng hệ thống nhận dạng kí tự tiếng việt gồm tất cả chữ thường và in hoa cũng như dấu và các kí tự đặc biệt khác. Qua đó mở rộng nghiên cứu và thực nghiệm trên văn bản tiếng Việt hoàn chỉnh.
.................
MỤC LỤC
LỜI CAM ĐOAN.. 1
MỤC LỤC.. 2
DANH MỤC HÌNH VẼ.. 6
DANH MỤC BẢNG BIỂU.. 7
DANH MỤC TỪ VIẾT TẮT.. 8
Mở đầu. 9
Chương 1. 10
GIỚI THIỆU.. 10
1.1. Đặt vấn đề. 10
1.2 Nội dung nghiên cứu của đồ án. 12
1.3. Một số ứng dụng của nhận dạng kí tự.12
1.4. Kết luận chương.13
CHƯƠNG 2. 14
CƠ SỞ LÝ THUYẾT CHO PHÂN ĐOẠN ẢNH VÀ THUẬT TOÁN NHẬN DẠNG KÍ TỰ 14
2.1. Giới thiệu chương. 14
2.2. Không gian màu RGB.14
2.3. Cơ bản về xử lý ảnh.15
2.3.1. Điểm ảnh.15
2.3.2 Độ phân giải ảnh.15
2.3.3. Mức xám của ảnh.16
2.3.4 Các hàm hiển thị ảnh trong Matlab 16
2.3.5 Các hàm khác được sử dụng trong đề tài 18
2.4. Cơ sở lý thuyết cho phân đoạn ảnh.19
2.4.1. Nhị phân hóa.19
2.4.2. Xử lý triệt nhiễu và nâng cao chất lượng ảnh 20
2.4.3. Chuẩn hóa kích thước ảnh.21
2.5. Phương pháp nhận dạng kí tự.22
2.5.1. Đối sánh mẫu.22
2.5.2 Đánh giá, so sánh phương pháp đôi sánh mẫu với các phương pháp khác.23
2.6. Kĩ thuật PCA.24
2.6.1 Giới thiệu.24
2.6.2. Một số khái niệm toán học sử dụng trong PCA.25
2.6.3 Thuật toán PCA.27
2.7. Kết luận chương.28
CHƯƠNG 3:. 29
PHÂN ĐOẠN ẢNH CHO NHẬN DẠNG VĂN BẢN.29
3.1 Giới thiệu chương.29
3.2 Tiền xử lý ảnh.29
3.3 Tách dòng.29
3.3.1 Ý tưởng.29
3.3.2 Ưu nhược điểm của phương pháp.30
3.3.3 Thuật toán.30
3.4 Tách từ.31
3.4.1 Ý tưởng.31
3.4.2 Thuật toán.32
3.5 Tách kí tự.32
3.5.1 Ý tưởng.33
3.5.2 Thuật toán. 33
3.6. Xác định giới hạn chính xác cho từng kí tự.33
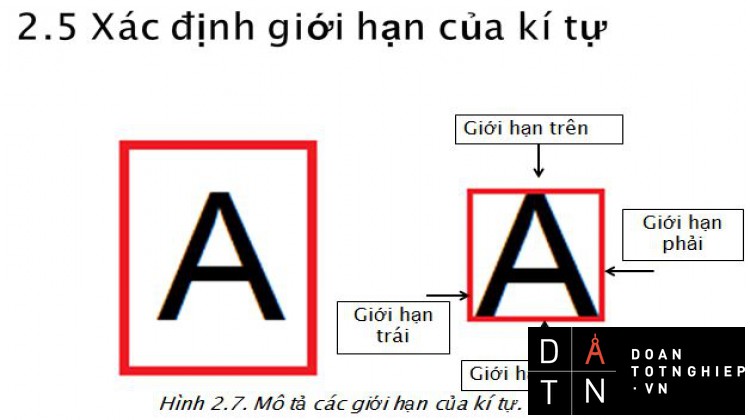
3.6.1. Xác định giới hạn trên và giới hạn dưới của kí tự.33
3.6.2. Xác định giới hạn phải và giới hạn trái của kí tự.34
3.7. Ánh xạ kí tự ảnh vào ma trận giá trị.34
3.7.1. Chuẩn hóa kích thước từng kí tự.34
3.7.2. Chuyển ma trận lưới pixel thành ma trận giá trị35
3.8. Kết luân chương.35
Chương 4:. 37
BỘ NHẬN DẠNG KÍ TỰ.37
4.1 Giới thiệu chương.37
4.2 Thuật toán PCA được sử dụng cho nhận dạng kí tự.37
4.3 Các bước để nhận dạng văn bản kí tự.39
4.4 Kết luận chương.41
Chương 5. 42
THỰC NGHIỆM ĐÁNH GIÁ KẾT QUẢ CHƯƠNG TRINH NHẬN DẠNG KÍ TỰ CHỮ IN HOA TIẾNG VIỆT.42
5.1. Giới thiệu.42
5.2 Môi trường thực nghiệm.42
5.3 Thực nghiệm với bộ phân đoạn ảnh.42
5.3.1 Tách dòng.43
5.3.2 Tách từ.43
5.3.3 Tách kí tự.44
5.4 Thực nghiệm với bộ nhận dạng kí tự.45
5.5 Thực nghiệm với chương trình nhận dạng văn bản.46
5.6 Kết luận chương.48
Kết luận và Hướng phát triển đề tài49
Tài liệu tham khảo. 50
PHỤ LỤC.. 51
DANH MỤC HÌNH VẼ
Hình 1.1 Sơ đồ khối hệ nhận dạng văn bản Tiếng Việt.11
Hình 2.1 Không gian màu RGB.. 15
Hình 2.2 ví dụ chuyển ảnh RGB sang ảnh đa mức xám và sau đó là ảnh nhị phân.19
Hinh 2.3 Ví dụ về nhiễu đốm.. 20
Hình 2.4 Ảnh sau khi áp dụng lọc trung vị.21
Hình 2.5 Kí tự A sau khi được chuẩn hóa với kích thước 15x10.21
Hình 2.6 Minh họa PCA :phép chiếu lên các trục tọa độ khác nhau có thể cho cùng cách nhìn rất khác nhau về cùng một dữ liệu.24
Hình 2.7 Minh họa PCA : tìm cá trụ tọa độ mới sao cho dữ liệu có độ biến thiên cao nhất.25
Hình 2.8 Các bước chính thực hiện PCA.27
Hình 3.1 Mô phỏng kết quả tách dòng.31
Hình 3.2 Ví dụ cho thuật toán tách từ.32
Hình 3.3 Mô tả vị trí của các vết cắt của kí tự.33
Hình 3.4 Mô tả giới hạn trên và giới hạn dưới của kí tự.34
Hình 4.2 Các bước thực hiện nhận dạng kí tự.40
Hình 5.1 Minh họa cho quá trình tách dòng.43
Hình 5.2 Ảnh các mẫu kí tự in hoa Tiếng Việt font chữ Arial.45
Hình 5.3 Ví dụ ảnh văn bản 1 để nhận dạng.46
Hinh 5.4 Văn bản sau khi nhận dạng xong.46
DANH MỤC BẢNG BIỂU
Bảng 2.1 Các hàm xử lý hình ảnh khác trong Matlab. 17
Bảng 2.2 Các phương pháp nội suy. 22
Bảng 5.1 Kết quả thực nghiệm tách dòng.43
Bảng 5.2 Kết quả thực nghiệm tách từ.44
Bảng 5.3 Kết quả thực nghiệm nhận dạng kí tự.47
DANH MỤC TỪ VIẾT TẮT
ORC: Optical Character Recognition.
PCA: Principal Component Analysis.
RGB: red-green-blue.
PEL: Picture Element.
SVM: support vector machine.
5.4 Thực nghiệm với bộ nhận dạng kí tự.
Đầu vào của bộ nhận dạng kí tự sẽ là các ảnh kí tự sau khi được tách ra từ văn bản cần nhận dạng. Các kí tự này sẽ được so sánh với các mẫu thông qua thuật toán PCA để tìm ra kí tự thích hợp.
Trong đồ án này, tôi chỉ sử dụng font chữ Arial để nhận dạng kí tự. Thông qua font chữ này ta có thể mô phỏng được nguyên lý làm việc cũng như thấy ngay được kết quả dễ dàng. Do đặc thù font này đơn giản, không có chân và các nét đều nhau nên việc nhận dạng chính xác hơn. Thông thường trong các văn bản hành chính, giấy tờ quan trọng cần nhận dạng người ta dùng font Arial hoặc các phông chữ đơn giản để dễ dàng nhận dạng. Ví dụ: giấy tờ xuất nhập hàng hóa của cục bưu chính được viết bằng font Arial, cỡ chữ 30, in đâm, màu đỏ, …
Để phát triển cho nhiều font khác nhau thì tôi xin đề xuất là tăng số mẫu kí tự của các font chữ khác cần nhận dạng, cũng như sử dụng thuật phân loại để phân loại ra các font khác nhau như vậy thì có thể nhận dạng nhiều font hơn.
|
A, Ă, Â, B, C, D, Đ, E, Ê, G, H, I, K, L, M, N, O, Ô, Ơ, P, Q, R, S, T, U, Ư, V, X, Y. |
Hình 5.2 Ảnh các mẫu kí tự in hoa Tiếng Việt font chữ Arial.
Tiền hành thực nghiệm nhận dạng kí tự với các kí tự riêng biệt trong bảng chữ cái ta rút ra một số nhận xét như sau.
- Nhận xét:
- Kí tự Q thường bị nhầm lẫn với kí tự O, do phân đuôi của kí tự Q hơi nhỏ so vơi kích thước chuẩn 15x10.
- Kí tự R có khả năng bị nhầm với P.
- Kí tự C có khả năng bị nhầm với O.
- Kí tự Ă có khả năng bị nhầm với Â.
- Các kí tự có độ chính xác cao là: A, B, D, E, G, H, I, K, L, M, N, O, Ơ, Ô, P, S, T, U, Ư, V, X, Y. Độ chính xác của các kí tự này gần như là 100%.
- Các kí tự thường bị nhầm lẫn có thể được khác phục trong bộ hậu xử lý để cho kết quả chính xác hơn.
5.5 Thực nghiệm với chương trình nhận dạng văn bản.
- Điều kiện thực nghiệm:Tôi thực nghiệm phân tách 10 văn bản gồm 100 dòng 742 từ, trong mỗi văn bản các dòng có cùng kích thước chữ.
Hình 5.3 Ví dụ ảnh văn bản 1 để nhận dạng.
Chương trình sau khi chạy, mỗi kí tự sẽ được ghi tuần tự vào file text, kết thúc ta sẽ nhận được 1 file text chứa văn bản sau khi nhận dạng như sau:
|
ANH EM MĂT TRƠI*#*ĐÂT NƯƠC HO HANG*#*CON NGƯƠI THIÊN NHIÊN*#*NGUYÊN CÔNG LI NH*#*MĂT TRƠI CO TUÔI THO NĂM TY NĂM*#*TRI ĐÂT CO TUÔI THO BÔN TY NĂM*#*CON NGUOI LA SINH WT THÔNG MINH NHÂT*#*CHI HĂNG CHU CUÔI*#*CÂ ĐA QUAN NƯƠC CÂ CAU LA TÊU*#*SÔNG LA CHO ĐÂU CHI NHÂN RIÊNG MINH*#* |
Hinh 5.4 Văn bản sau khi nhận dạng xong.
- Kết quả thực nghiệm:
|
Văn bản |
Số kí tự |
Số kí tự đúng |
Tỉ lệ (%) |
|
1 |
274 |
256 |
93,43066 |
|
2 |
203 |
196 |
96,55172 |
|
3 |
244 |
238 |
97,54098 |
|
4 |
230 |
218 |
94,78261 |
|
5 |
265 |
260 |
98,11321 |
|
6 |
235 |
227 |
96,59574 |
|
7 |
292 |
275 |
94,17808 |
|
8 |
253 |
245 |
96,83794 |
|
9 |
272 |
254 |
93,38235 |
|
10 |
257 |
244 |
94,94163 |
|
Tổng cộng |
2525 |
2413 |
95,56436 |
Bảng 5.3. Kết quả thực nghiệm nhận dạng kí tự.
Ø Nhận xét:
- Ta có thể thấy các chữ bị nhận dạng nhầm do không tách kí tự được ở đây là TRAI, VÂT, CÂY, VA,…
- Các kí hiệu *#* tương ứng kết thúc 1 dòng trong văn bản.Các sai sót này có thể được chỉnh sửa trong bộ hậu xử lý trước khi đưa ra văn bản chính xác.
- Kết quả nhận dạng kí tự có độ chính xác trên 95%, có thể chấp nhận được. Tuy nhiên cần phải cải thiện nhiều.
5.6 Kết luận chương.
Nhận dạng kí tự in hoa Tiếng Việt là nhận dạng 29 kí tự in hoa Tiếng Việt gồm: A, Ă, Â, B, C, D, Đ, E, Ê, G, H, I, K, L, M, N, O, Ô, Ơ, P, Q, R, S, T, U, Ư, V, X, Y. Qua thực nghiệm, nhận thấy các kí tự Q và O, C và O, R và P thường bị nhầm lẫn với nhau, ngoài ra các kí tự khác có độ chính xác khá cao.
Chương trình test có thời gian đáp ứng khá nhanh, kết quả nhận được có độ chính xác trên 90%. Hệ thống còn một số hạn chế về tách từ và tách kí tự gián tiếp làm giảm khả năng nhận dạng của hệ thống. Cần áp dụng các kĩ thuật tốt hơn để làm tăng khả năng tách từ và tách kí tự, như vậy có thể tăng độ chính xác lên hơn 90% như bây giờ.
Kết luận và Hướng phát triển đề tài
Trong đồ án này, tôi đã trình bày những lý thuyết cơ bản về phân đoạn ảnh, và nhận dạng kí tự. Từ đó áp dụng vào bài toán nhận dạng chữ in hoa tiếng Việt. Qua mô phỏng thực nghiệm:
- Quá trình tách dòng cho kết quả chính xác 98%.
- Quá trình tách từ cho kết quả chính xác 96%.
- Quá trình tách kí tự và nhận dạng cho kết quả chính xác 95,5%.
Kết quả mô phỏng bước đầu có thể chấp nhận được với độ chính xác trên 95%. Thuật toán tách dòng cho độ chính xác tốt; thuật toán tách từ, tách kí tự có độ chính xác tương đối; cần được cải tiến và khắc phục thêm
Trong tương lai, tôi sẽ tiếp tục nghiên cứu và phát triển để nâng cao chất lượng hệ thống cả về độ chính xác và tốc độ; có thể cải thiện quá trình tách kí tự để đạt độ chính xác hơn. Từng bước nghiên cứu và xây dựng hệ thống nhận dạng kí tự tiếng việt gồm tất cả chữ thường và in hoa cũng như dấu và các kí tự đặc biệt khác. Qua đó mở rộng nghiên cứu và thực nghiệm trên văn bản tiếng Việt hoàn chỉnh.
Tài liệu tham khảo
[1] Nguyễn Hoàng Hải-Nguyễn Khắc Kiểm, “Lập trình Matlab”, NXB Khoa học và kỹ thuật.
[2] Học viện công nghệ bưu chính viễn thông, “Xử lý ảnh” ( cho sinh viên hệ đào tạo từ xa), Hà Nội-2006.
[3] Ngô Văn Sỹ (Đại học Bách Khoa Đà Nẵng), “Nhận dạng kí tự quang học bằng mạng noron”, tạp chí khoa học và công nghệ, đại học Đà Nẵng số 4(27).2008.
[4] Jonathon Shlens, “A Tutorial on Principal Component Analysis”, Center for Neural Science, New York University New York city, Systems Neurobiology Laboratory( Dated: April 22, 2009, version 3.01).
[5] http://vi.wikipedia.org/wiki.
[6] mathworks.com