LUẬN VĂN TỐT NGHIỆP Hệ thống nhúng điều khiển xe lăn bằng giọng nói

NỘI DUNG ĐỒ ÁN
ĐẠI HỌC QUỐC GIA THÀNH PHỐ HỒ CHÍ MINH
TRƯỜNG ĐẠI HỌC BÁCH KHOA
KHOA ĐIỆN – ĐIỆN TỬ
BỘ MÔN ĐIỀU KHIỂN TỰ ĐỘNG
LUẬN VĂN TỐT NGHIỆP
Hệ thống nhúng điều khiển xe lăn bằng giọng nói

NHIỆM VỤ CỦA LUẬN VĂN
Nhận dạng tiếng nói là đề tài nhận được sự quan tâm, nghiên cứu của khá nhiều nhà khoa học trong suốt những thập niên vừa qua. Kết quả của những sự nghiên cứu này đã được ứng dụng vào các phần mềm nhận dạng tiếng Anh và gần đây chúng ta đã có phần mềm nhận dạng tiếng Việt.
Tuy nhiên, trong các hệ thống nhúng, thì việc điều khiển bằng giọng nói còn chưa phổ biến, bởi nhiều nguyên nhân. Một trong những nguyên nhân chính các loại vi điều khiển hiện nay thường không đủ tốc độ, bộ nhớ và sự ổn định cần thiết để thực hiện các giải thuật phức tạp nhận dạng đã ứng dụng thành công trên máy tính.
Trong suốt hơn 4 năm học tại trường Đại học Bách Khoa, em đã được học rất nhiều kiến thức về điều khiển tự động, xử lý số, lập trình C, assembly… em muốn ứng dụng những kiến thức này để thực hiện một đề tài có ý nghĩa. Vì vậy mà em đã chọn đề tài « Hệ thống nhúng điều khiển xe lăn bằng giọng nói » là đề tài luận văn tốt nghiệp. Đây là một đề tài có ý nghĩa nhân văn sâu sắc, giúp ích cho những người tàn tật không có khả năng điều khiển xe lăn bằng tay hoặc chân.
Trên cơ sở nội dung của đề tài như trên thì nhiệm vụ của em là :
¾ Tìm hiểu hệ thống nhận dạng tiếng nói, các bước : tách từ, trích đặc trưng, huấn luyện, nhận dạng.
¾ Lựa chọn và tìm hiểu loại vi điều khiển phù hợp với giải thuật ở trên.
¾ Thực hiện giải thuật trên vi điều khiển.
¾ Thi công hệ thống nhúng nhận dạng tiếng nói và mạch công suất điều khiển
động cơ.
¾ Thi công mô hình xe lăn.
CHƯƠNG 1
GIỚI THIỆU TỔNG QUÁT VỀ ĐỀ TÀI
CHƯƠNG 1
GIỚI THIỆU TỔNG QUÁT VỀ ĐỀ TÀI
1.1 Mở đầu
Tiếng nói của con người có đặc điểm là biến đổi tùy thuộc vào người nói, giới tính, tuổi tác, trạng thái của người nói và rất dễ bị ảnh hưởng bởi môi trường xung quanh.Một người thường không bao giờ phát ra hai tiếng hoàn toàn giống nhau được.
Vì vậy mà người thực hiện hệ thống nhận dạng tiếng nói phải xác định rõ đối tượng nhận dạng là một tập các tín hiệu biến đổi rất rộng, và phải xác định được các yếu tố nhằm phân biệt giữa tập hợp của từ này với tập hợp của từ khác.
Khi thực hiện một hệ thống nhúng nhận dạng tiếng nói, người thực hiện còn phải đối mặt với các vấn đề như là tốc độ xử lý, bộ nhớ và sự ổn định của vi điều khiển. Hơn nữa, các linh kiện rẻ tiền được bán ở Việt Nam thường thiếu độ tin cậy. Đây là một trở ngại rất lớn khi em thực hiện đề tài này.
Ngoài ra, là một sinh viên ngành Điều khiển tự động, em không được đào tạo chuyên sâu về lĩnh vực xử lý tín hiệu và không có được các thiết bị máy móc cần thiết cho việc nghiên cứu cho nên khi thực hiện đề tài này em đã gặp không ít khó khăn.
Xác định được những thử thách phải đương đầu, em đã tham khảo các tài liệu sưu tầm được trên mạng internet, luận văn các khóa trên kết hợp những kiến thức đã học để chọn được giải thuật có hiệu quả khắc phục các yếu tố trở ngại trên.
Chương này sẽ cung cấp cho người đọc cái nhìn tổng quát về toàn bộ đề tài.
1.2 Tổng quát về hệ thống
Hình 1.1 Tổng quát về hệ thốnga. Tín hiệu tiếng nói sau khi qua micro được khuếch đại cho phù hợp với bộ ADC của vi điều khiển đồng thời loại bỏ đi những tần số cao, chống hiện tượng chồng lấn phổ.
b. Vi điều khiển ATmega32 đóng vai trò xử lý và nhận dạng tiếng nói, sau đó phát tín hiệu điều khiển mạch công suất.
c. Mạch công suất là các cầu H, có tác dụng điều khiển 2 động cơ của xe lăn. d. Xe lăn : mô hình thu nhỏ của xe lăn thật với 2 động cơ DC công suất nhỏ.
1.3 Hệ thống nhận dạng tiếng nói :
Quá trình cơ bản của nhận dạng tiếng nói bao gồm : tách từ, trích đặc trưng và nhận dạng. Cả 3 bước này đều được thực hiện hoàn toàn trên vi điều khiển ATmega32 của hãng Atmel. Đây là loại điều khiển quen thuộc, phổ biến trên thị trường Việt Nam. Hình sau mô tả một hệ thống nhận dạng tiếng nói :
Hình 1.2 Hệ thống nhận dạng tiếng nói
a. Tín hiệu được lấy từ bộ ADC với tần số lấy mẫu là 5 KHz.
b. Bộ tách từ có tác dụng phát hiện có từ được nói hay không, khi có từ thì bộ
tách từ điều khiển cho bộ Trích đặc trưng làm việc.
c. Bộ trích đặc trưng có tác dụng tìm ra các đặc điểm riêng của từ vừa nói rồi cung cấp cho bộ so sánh.
d. Bộ so sánh lấy các đặc trưng đã nhận được đem so sánh với các mẫu đã được huấn luyện sẵn để cho ra kết quả.
e. Kết quả là một trong 5 lệnh điều khiển : Tới, Dừng, Trái, Phải, Lùi.
Quá trình tách từ được thực hiện như sau :Hình 1.3 Quá trình tách từ
a. Tín hiệu sau khi lấy mẫu được bình phương rồi cộng dồn vào năng lượng của frame. Độ dài mỗi frame ở đây chúng ta chọn là 10 ms ứng với 50 mẫu.
b. Bộ so sánh 1 : sẽ so sánh năng lượng của frame với năng lượng nhiễu đã lưu trước đó, và cung cấp kết quả cho bộ so sánh 2.
c. Bộ so sánh 2 so sánh khoảng thời giữa điểm bắt đầu và điểm kết thúc của tín hiệu và thời gian tối thiểu của một tiếng nói, để xuất ra kết quả là có từ được nói hay không.
Quá trình lấy đặc trưng được thực hiện như sau :
Hình 1.4 Quá trình lấy đặc trưng
a. Bộ đếm mẫu : đếm số mẫu của tín hiệu nếu có từ. Bộ này xác định số mẫu còn có nghĩa là thời gian nói.
b. Zero-crossing : Xác định số lần tín hiệu qua điểm ‘0’ trung bình.
c. Các bộ lọc : gồm có 9 bộ lọc IIR loại Chebyshev 2, bậc 4, độ suy hao ngoài băng thông là 60 dB phân bố đều từ 100 Hz đến 1900 Hz.
d. Tích lũy năng lượng : tính năng lượng trên các dải tần, trong một khoảng thời gian xác định. Kết quả cho ra là phân bố năng lượng trên miền tần số và miền thời gian.
Quá trình nhận dạng được thực hiện như sau :Hình 1.5 Quá trình nhận dạng
a. Ước lượng xác suất theo thời gian nói cho từng từ theo phân phối chuẩn.
b. Ước lượng xác suất theo số lần qua điểm ‘0’ trung bình cho từng từ theo phân phối chuẩn.
c. Khoảng cách ở đây chúng ta dùng phương pháp hồi quy tuyến tính, để tính hệ số tương quan giữa phân bố năng lượng của từ cần dạng và các mẫu đã được huấn luyện.
d. Bộ so sánh : so sánh các kết quả nhân để tìm ra
................................................................
CHƯƠNG 2
SƠ LƯỢC VỀ TIẾNG NÓI
2.1 Mở đầu
Tiếng nói cùng với chữ viết là hai thành phần cơ bản nhất của ngôn ngữ, nó hình thành trước chữ viết và phát triển trong suốt lịch sử phát triển của loài người. Tiếng nói đã, đang và sẽ luôn là phương tiện giao tiếp chủ yếu của con người bởi lẽ giao tiếp bằng tiếng nói là cách thức đơn giản, tự nhiên và đóng vai trò quan trọng trong đời sống con người.
Ngày nay, cùng với sự phát triển của khoa học kỹ thuật, các nhà khoa học đã tạo ra các loại máy móc dần thay thế lao động chân tay, trí óc của con người nhưng việc giao tiếp giữa người với máy vẫn phổ biến là những thao tác phức tạp và cần được đào tạo. Chính vì lẽ đó mà việc nghiên cứu phát triển các loại thiết bị có khả năng giao tiếp với con người qua giọng nói đã và đang nhận được sự quan tâm của nhiều nhà khoa học trên thế giới, cũng như người tiêu dùng. Các ứng dụng này đã được áp dụng vào điện thoại di động, máy tính,… tuy nhiên mức độ phổ biến vẫn còn rất hạn chế.
2.2 Sự tạo thành tiếng nói
Tiếng nói là các chuỗi âm thanh được phát ra từ bộ máy phát âm của con người để trao đổi tư tưởng, tình cảm giữa các thành viên trong xã hội. Đây chính là một trong các phương tiện trao đổi thông tin quan trọng nhất của con người.
Như vậy, thực sự thì tiếng nói chỉ là một chuỗi âm thanh lan truyền trong không khí ở dạng sóng cơ học, do đó nó có phần giống với các âm thanh khác trong thế giới tự nhiên.
Vì thế, khi xem xét tiếng nói, đầu tiên ta phải xét nó ở khía cạnh bản chất vật lý của nó. Tuy nhiên, sự khác biệt quan trọng của tiếng nói so với các âm thanh khác được tạo nên bản chất sinh lý của tiếng nói. Tiếng nói được phát ra từ bộ máy phát âm của loài người nên nó hết sức tinh vi, phức tạp hơn nhiều âm thanh khác. Ngoài ra, tiếng nói là âm thanh được dùng để giao tiếp thường nhật trong xã hội nên nó phải được xem xét về mặt xã hội, chức năng của nó trong một cộng đồng ngôn ngữ nhất định.
Việc xử lý thông tin chứa trong tín hiệu tín nói nhằm truyền, lưu trữ tín hiệu này hoặc tổng hợp, nhận dạng tiếng nói.
Mục đích :
Mã hóa tiếng nói một cách hiệu quả để truyền và lưu trữ tiếng nói.
Tổng hợp, nhận dạng tiếng nói tiến đến giao tiếp người-máy bằng
tiếng nói.
Như vậy, tất cả các ứng dụng của tiếng nói đều phải dựa trên các kết quả phân
tích tiếng nói. Thực tế cho thấy, các nghiên cứu được tiến hành để xử lý tiếng nói yêu cầu những hiểu biết trên nhiều lĩnh vực đa dạng : ngữ âm học, ngôn ngữ học, xử lý tín hiệu…
Phân biệt tiếng nói với các âm thanh khác :
Tiếng nói được phân biệt với các âm thanh khác bởi đặc tính âm học có cơ chế từ
nguồn gốc tạo tiếng nói.
Có 2 loại nguồn âm :
Nguồn tuần hoàn : dây thanh rung
o Dây thanh rung : vocal folds , vocal cords.
o Chu kỳ tuần hoàn: chu kỳ rung của dây thanh.
o Nguồn tuần hoàn: chủ yếu tương ứng với nguyên âm.
Nguồn tạp âm : dây thanh không rung, chủ yếu là phụ âm.
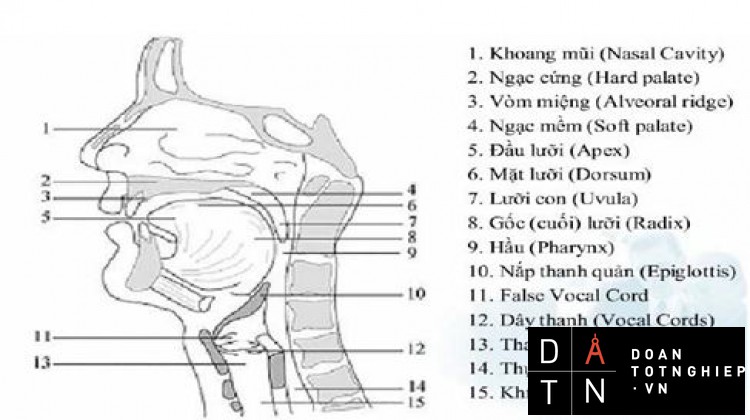
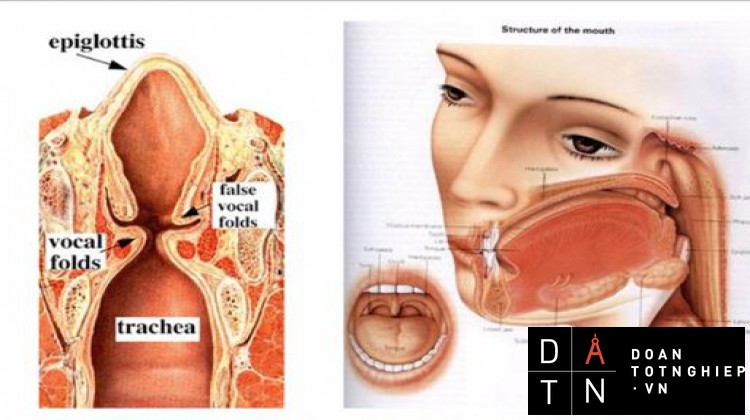
Cấu trúc bộ máy phát âm:
Hình 2.1.Bộ máy phát âm Khoảng không giữa dây thanh và thanh quản được gọi là thanh môn.
Nguồn tuần hoàn : vị trí nằm ở thanh môn.
Nguồn tạp âm : vị trí phụ thuộc vào âm được tạo ra, không nằm ở
thanh môn.
Ví dụ : âm ‘s’ vị trí nằm ở khoang miệng.
Nói thì thào: dây thanh không rung, thanh môn gần như bị khép lại.
Hệ thống đằng sau thanh môn ( gồm phổi, khí quản, phế quản ) có vai
trò như một nguồn năng lượng để tạo tiếng nói.
Tuyến âm ( vocal tract ) : toàn bộ bộ máy phát âm, tính từ thanh môn
trở lên.
Thanh môn và dây thanh:
Hình 2.3.Dây thanh và thanh mônHình 2.4.Hình dạng thanh môn ở các vị trí
Hình 2.5.Sơ đồ khối bộ máy phát âm
Khoang mũi ( nasal tract) : bắt đầu từ vòm miệng mềm và kết thúc ở lỗ mũi. Khí vòm miệng mềm hạ xuống khoang mũi ghép song song với khoang miệng để tạo âm mũi.
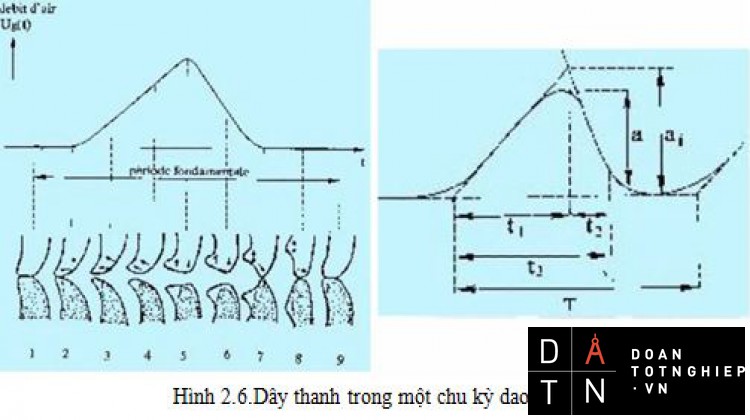
Dây thanh trong một chu kỳ dao động : Thể tích không khí vận chuyển qua thanh môn trong một đơn vị thời gian được gọi là thông lượng ( khoảng 1cm3/s). Khi dây thanh rung với chu kỳ To thì thông lượng cũng biến đổi tuần hoàn theo chu kỳ này.
Gọi To là chu kỳ cơ bản => tần số cơ bản
- fo phụ thuộc vào giới tính ( nữ > nam ) và lứa tuổi ( trẻ > già ).
- Thay đổi fo sẽ thay đổi thanh điệu.
- fo ảnh hưởng đến ngữ điệu của câu.
Hình 2.6.Dây thanh trong một chu kỳ dao động
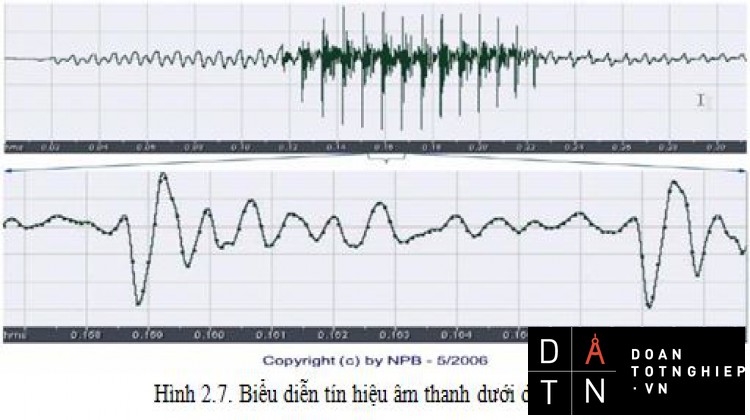
2.3 Biểu diễn tín hiệu tiếng nói
Có 3 phương pháp cơ bản để biểu diễn tín hiệu tiếng nói:
- Biểu diễn dưới dạng sóng theo thời gian.
- Biểu diễn trong miền tần số : chính là phổ của tín hiệu tiếng nói.
- Biểu diễn trong không gian 3 chiều : sonagram ( spectrogram ). Biểu diễn dưới dạng sóng theo thời gian:
Hình 2.7. Biểu diễn tín hiệu âm thanh dưới dạng sóng
Phần tín hiệu ứng với âm vô thanh là không tuần hoàn, ngẫu nhiên và có biên độ năng lượng nhỏ so với biên độ năng lượng của một nguyên âm ( gần bằng 1/3).
Để lưu trữ âm thanh dưới dạng sóng, định dạng thông dụng nhất là *.wav với:
- Tần số lấy mẫu thường gặp là 8KHz, 10KHz, 11,25KHz, 16KHz, 22,05KHz,…
- Độ phân giải ( số bit/ mẫu) : thường là 8 hay 16 bit.
- Số kênh : 1 kênh ( mono ) hoặc 2 kênh ( stereo ).
Khi thu tiếng nói bằng micro khác loại thì dạng sóng tiếng nói cũng có phần khác nhau. Hình ảnh sau là dạng sóng tiếng nói của cùng một âm được thu bằng 2 loại micro khác nhau: 1 loại là dynamic microphone và loại kia là condenser microphone.
Hình 2.8 Dạng sóng tiếng nói thu được từ 2 loại micro khác nhau
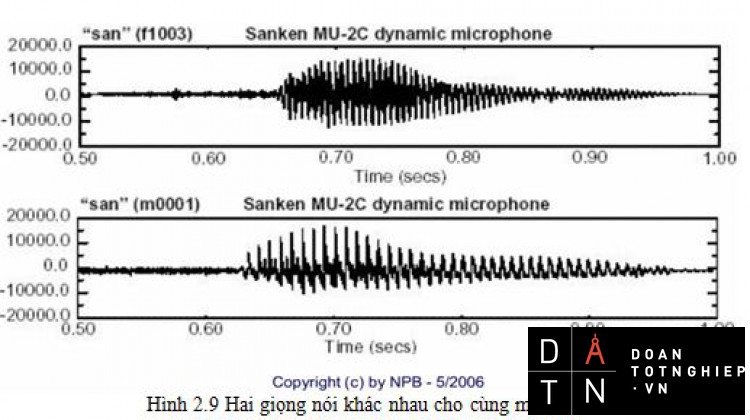
Hay cùng một âm nhưng do 2 người khác nhau nói thì dạng sóng tiếng nói cũng có sự sai khác đáng kể.
Hình 2.9 Hai giọng nói khác nhau cho cùng một âmVà thậm chí, cùng một âm do cùng một người nói ở những thời gian khác nhau cũng không phải hoàn toàn giống nhau.
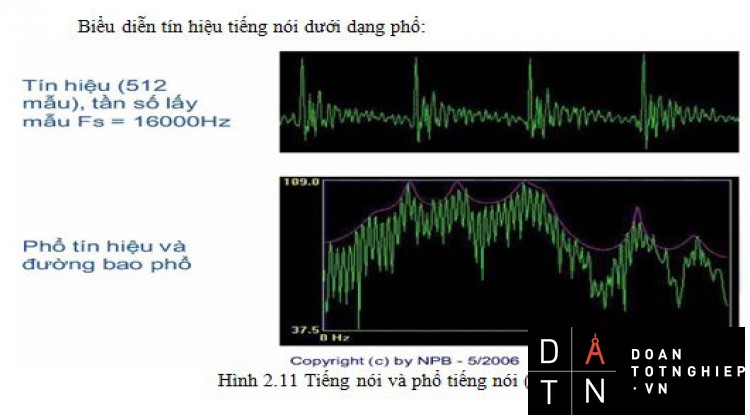
Hình 2.10.Cùng một âm do cùng một người nóiBiểu diễn tín hiệu tiếng nói dưới dạng phổ:
Hình 2.11 Tiếng nói và phổ tiếng nói (1)Hình 2.12.Tiếng nói và phổ tiếng nói (
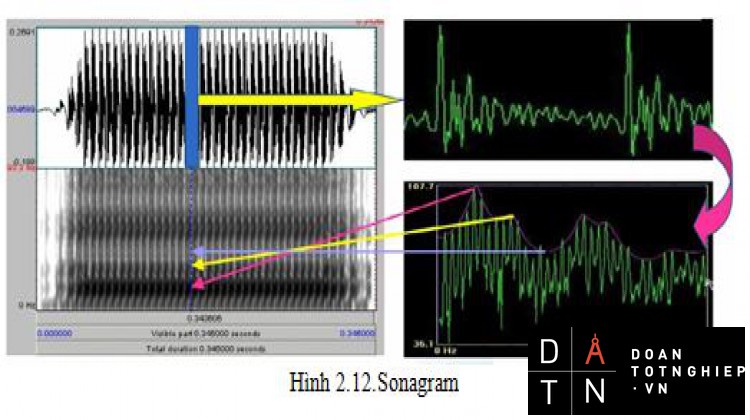
Biểu diễn tín hiệu tiếng nói dưới dạng Sonagram: Sonagram biểu diễn tín hiệu tiếng nói trong đồ thị 2 chiều:
- Trục thời gian là trục nằm ngang.
- Trục tần số là trục thẳng đứng.
- Biên độ phổ được biểu diễn bằng độ đậm nhạt hay màu sắc.
Hình 2.12.Sonagram
Để vẽ Sonagram, ta thực hiện các bước sau:
- Chia tín hiệu tiếng nói thành các khung (frame) ứng với các cửa số quan sát, ví
dụ :
+ Độ dài mỗi frame hay cửa sổ là 10ms.
+ Nếu tần số lấy mẫu là 16 KHz thì mỗi cửa sổ có 160 mẫu.
+ Mỗi cửa sổ có 1 đoạn chườm lên nhau ( khoảng nhỏ hơn ½ frame).
- Vẽ phổ của khung tín hiệu trên trục thẳng đứng, biên độ phổ được biễu diễn
bằgn độ đậm nhạt của màu sắc.
- Vẽ tiếp theo trục thời gian bằng cách chuyển qua cửa sổ tiếp theo.
Hình 2.14.Frame tín hiệu tiếng nói2.4 Formant và Antiformant
Tuyến âm được coi như một hốc cộng hưởng, có tác dụng tăng cường một số tần số nào đó. Những tần số được tăng cường được gọi là các Formant. Nếu tuyến âm được coi là hoang miệng thì khoang mũi cũng là hốc cộng hưởng. Khoang mũi được mắc song song với khoang miệng nên sẽ làm suy giảm một số tần số nào đó. Những tần số bị suy giảm được gọi là các phản Formant (Antiformant).
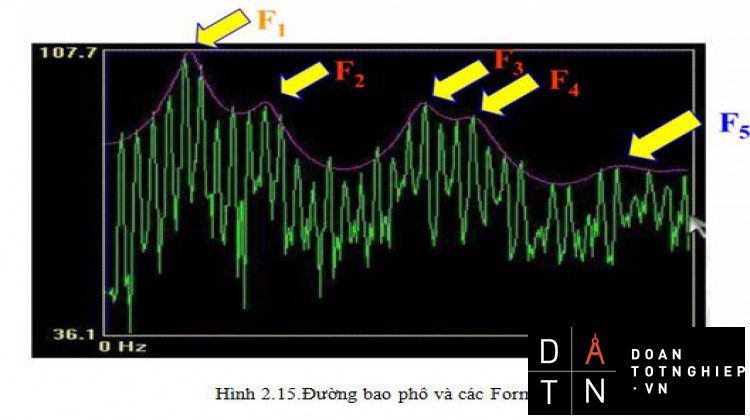
Hình 2.15.Đường bao phổ và các Formant
Mỗi Formant chính là đỉnh của âm hữu âm. Ta có thể tính đến Formant thứ 5 nhưng quan trọng nhất là hai Formant đầu tiên.
Cùng một người phát ra cùng một âm thì các Formant vẫn có thể khác nhau. Do đó nếu chỉ căn cứ vào các Formant để đặc trưng cho âm hữu thanh thì chưa chính xác mà phải dựa vào sự phân bố tương đối giữa các Formant.
Để xác định các Formant, ta không nên dựa trực tiếp vào phổ tiếng nói vì sẽ thiếu chính xác mà nên dựa vào đường bao phổ. Đó chính là đáp ứng tần số của tuyến âm.
Đối với âm vô thanh thì vị trí nguồn âm nằm đâu đó trong tuyến âm, phụ thuộc vào âm được phát ra. Phổ của âm vô thanh bằng phẳng trong phạm vi rộng từ 0 KHz đến
8 KHz.
......................................................
CHƯƠNG 6
HUẤN LUYỆN VÀ NHẬN DẠNG TIẾNG NÓI
6.1 Mở đầu
Huấn luyện là một bước cực kỳ quan trọng đối với hệ thống nhận dạng tiếng nói. Chúng ta đều biết rằng con người không thể phát ra những tiếng nói giống nhau hoàn
toàn được, một người vừa nói một tiếng, nhưng khi có ai đó yêu cầu anh ta lặp lại thì anh chỉ có thể nói một tiếng nghe có vẻ giống tiếng trước đó thôi chứ dạng sóng có thể rất khác nhau. Ví dụ, cùng nói một từ ‘Trái’ nhưng khoảng thời gian nói có thể dao động từ
140 ms cho đến 300 ms và bên cạnh đó là rất nhiều sự thay đổi trong biên độ, tần số… Con người chúng ta luôn đi tìm ra cái gì đã làm cho 2 tiếng khác nhau đó nghe có
vẻ giống nhau, câu trả lời là các đặc trưng. Nhưng thực tế cho thấy các đặc trưng mà chúng ta thu được không bao giờ là lý tưởng, nó luôn bao gồm cả phần riêng biệt của từ cộng với một phần bị biến đổi trong đó. Vì lý do trên mà chúng ta cần một bước huấn luyện.
Bước huấn luyện đầu tiên sẽ cung cấp cho chúng ta cái nhìn tổng quát về đối tượng, khả năng biến đổi của nó, từ đó bằng khả năng tư duy của con người, chúng ta sẽ tìm ra cái chung nhất không bị biến đổi của đối tượng sau đó ‘dạy’ cho máy biết cách phân biệt các từ mà nó cần nhận dạng.
Có một điều quan trọng nữa là : phương pháp huấn luyện phải phù hợp với phương pháp trích đặc trưng để đạt kết quả tốt nhất. Trong đề tài này, em sử dụng 3 loại đặc trưng là thời gian nói, số lần qua điểm ‘0’ trung bình (zero-crossing rate) và phân bố năng lượng theo miền tần số.
Đối với đặc trưng về thời gian nói và zero-crossing rate em sử dụng phương pháp xấp xỉ phân bố chuẩn để tính xác suất rơi vào các miền đã định trước. Còn đối với đặc trưng về phân bố năng lượng thì phương pháp VQ sẽ là phương pháp phù hợp nhất.
6.2 Phương pháp huấn luyện theo phân phối chuẩn
Các đặc trưng về thời gian nói và zero-crossing rate sẽ giúp chúng ta ‘sơ loại’ các từ cần nhận dạng. Ví dụ : từ ‘Dừng’ có thời gian nói rất ngắn, không bao giờ vượt quá
180 ms, nếu từ cần nhận dạng có độ dài trên 180 ms thì khả năng là từ ‘Dừng’ gần như là
không có. Một ví dụ nữa là từ ‘Trái’ và ‘Phải’ luôn luôn có zero-crossing rate nhỏ hơn 4, vì vậy mà hệ thống sẽ không được phép cho kết quả là ‘Trái’ hoặc ‘Phải’ nếu zero- crossing rate lớn hơn 4.
Vậy thì câu hỏi đặt ra là làm sao chúng ta biết được các đặc điểm như trên vừa nêu và làm sao chúng ta có thể sử dụng được chúng và việc ‘dạy’ cho hệ thống biết phân biệt từ ?
Câu trả lời cho câu hỏi này là phương pháp xấp xỉ theo phân phối chuẩn.
6.2.1 Đôi nét về lịch sử của phương pháp
Phân phối chuẩn được nhà toán học nổi tiếng người Pháp là Abraham de Moivre phát hiện và đưa ra trên báo năm 1733. Sau đó, Laplace là người đã mở rộng kết quả này và xuất bản trong cuốn sách Analytical Theory of Probabilities năm 1812. Ngày nay người ta còn gọi đây là định lý Moivre-Laplace. Năm 1809, Gauss đã dùng quy luật phân phối này để chứng minh phương pháp rất quan trọng là phương pháp bình phương tối thiểu.
Nhà bác học Gauss cũng chỉ ra rằng quy luật phân phối này phù hợp với các hiện tượng tự nhiên. Thật vậy, các nhà khoa học sau này đã kiểm chứng rằng hầu hết các hiện tượng trong tự nhiên đều tuân theo một cách chính xác quy luật này. Vì vậy mà phối phối chuẩn đã được ứng dụng và rất nhiều lĩnh vực như : y tế, kỹ thuật, kiến trúc, đo lường…
6.2.2 Ứng dụng phương pháp vào đề tài
Phân phốichuẩn giả thiết rằng các dữ liệu sẽ tập trung xung quanh giá trị trung bình của chúng, xác suất sẽ cao nhất tại giá trị trung bình và giảm dần qua 2 bên. Đồ thị của hàm mật độ xác suất sẽ có dạng ‘hình chuông’ :
Hình 6.1 Hàm mật độ xác suất
Công thức sau miêu tả hàm mật độ xác suất của phân phối chuẩn tại điểm x :
Với :
- σ : là độ lệch chuẩn, được định nghĩa là căn bậc 2 của phương sai. Phương sai là
trung bình của bình phương khoảng cách của mỗi điểm dữ liệu tới điểm trung bình.
- μ : giá trị trung bình của tập các tín hiệu quan sát.
Như vậy, muốn tính được xác suất mà dữ liệu nhỏ hơn một giá trị nào đó chúng chỉ cần lấy tích phân hàm mật độ xác suất trên :
Trở về với đề tài, mục tiêu của chúng ta là tính được xác suất mà các đặc trưng sẽ rơi vào các miền và trong mỗi miền thì phân bố xác suất giữa các từ sẽ như thế nào. Các bước thực hiện sẽ như sau :
• Đầu tiên chúng ta giả sử biến ngẫu nhiên cần khảo sát tuân theo quy luật phân phối chuẩn hay còn gọi là quy luật hình chuông.
• Tiếp theo, chúng ta khảo sát một lượng khá lớn mẫu tín hiệu, số lượng càng lớn thì độ chính xác càng cao.
• Kế đến, chúng ta tính các giá trị trung bình, độ lệch chuẩn của các mẫu trên.
• Sau đó, chúng ta cần phân vùng cho các đặc trưng, việc này phụ thuộc vào đặc tính của đặc trưng.
• Chúng ta dùng các phần mềm tính toán để tính ra xác suất mà đặc trưng của chúng ta rơi vào từng vùng đã chọn ở trên.
• Bước cuối cùng là bước cân bằng xác suất giữa các từ trong từ điển trên từng vùng.
6.2.3 Kết quả huấn luyện
sau :
Thực hiện theo các bước trên, với trên 2000 điểm dữ liệu, em đã thu được kết quả
|
Lệnh |
Thời gian nói |
Zero-crossing rate |
||
|
Trung bình |
Độ lệch chuẩn |
Trung bình |
Độ lệch chuẩn |
|
|
Tới |
1207.75 |
118.7753 |
3.81068727 |
0.3388991 |
|
Dừng |
619.5 |
54.968067 |
4.40129058 |
0.45273502 |
|
Trái |
1354.674 |
161.1375 |
3.08947418 |
0.21370543 |
|
Phải |
1220.167 |
140.0608 |
2.97890288 |
0.17085631 |
|
Lùi |
1276.204 |
153.0478 |
4.4211174 |
0.40027118 |
Công cụ tính toán ở đây em sử dụng là phần mềm R. Đây là một phần mềm mã nguồn mở, miền phí nhưng khả năng tính toán của nó không thua kém các phần mềm thương mại hiện nay.
Chỉ bằng một lệnh rất đơn giản, chúng ta đã có được giá trị xác suất cần tính.
pnorm(b, mean=1207.75, sd=118.7753)-pnorm(a, mean=1207.75, sd=118.7753)
Trong đó:
• mean là giá trị trung bình của tập hợp
• sd là độ lệch chuẩn
• a,b là các cận lấy tích phân.
Sau khi cân bằng xác suất giữa các từ trong từng vùng, chúng ta có được kết quả
như sau :
|
Số mẫu |
Tới |
Lùi |
Dừng |
Trái |
Phải |
|
500 |
0 |
0 |
1000 |
0 |
0 |
|
550 |
0 |
0 |
1000 |
0 |
0 |
|
600 |
0 |
0 |
1000 |
0 |
0 |
|
650 |
0 |
0.1 |
1000 |
0 |
0.1 |
|
700 |
0.1 |
0.4 |
999 |
0.1 |
0.6 |
|
750 |
1.5 |
5.7 |
983 |
1.7 |
8.02 |
|
800 |
41.7 |
102 |
670 |
32.4 |
154 |
|
850 |
167 |
273 |
34.4 |
91.5 |
434 |
|
900 |
223 |
260 |
0.3 |
92.8 |
425 |
|
950 |
269 |
241 |
0 |
92.8 |
397 |
|
1000 |
309 |
227 |
0 |
95.1 |
369 |
|
1050 |
338 |
218 |
0 |
101 |
343 |
|
1100 |
354 |
215 |
0 |
110 |
321 |
|
1150 |
355 |
218 |
0 |
125 |
302 |
|
1200 |
510 |
168 |
0 |
110 |
212 |
|
1250 |
311 |
240 |
0 |
179 |
270 |
|
1300 |
269 |
257 |
0 |
222 |
253 |
|
1350 |
216 |
274 |
0 |
278 |
231 |
|
1400 |
160 |
289 |
0 |
346 |
205 |
|
1450 |
107 |
296 |
0 |
424 |
173 |
|
1500 |
64.8 |
293 |
0 |
505 |
137 |
|
1550 |
35.1 |
278 |
0 |
584 |
103 |
|
1600 |
17.1 |
254 |
0 |
657 |
72.7 |
|
1650 |
7.48 |
224 |
0 |
720 |
48.6 |
|
1700 |
2.97 |
191 |
0 |
775 |
30.9 |
|
1750 |
1.07 |
160 |
0 |
821 |
18.7 |
|
1800 |
0.4 |
130 |
0 |
859 |
10.9 |
|
Rate |
Tới |
Lùi |
Dừng |
Trái |
Phải |
|
2.7-2.8 |
6 |
0.1 |
0.8 |
355 |
638 |
|
2.8-2.9 |
7.8 |
0.2 |
0.9 |
361 |
630 |
|
2.9-3.0 |
12.5 |
0.3 |
1.4 |
392 |
593 |
|
3.0-3.1 |
23.8 |
0.7 |
2.6 |
450 |
523 |
|
3.1-3.2 |
52.3 |
1.9 |
5.8 |
524 |
416 |
|
3.2-3.3 |
124 |
5.8 |
14.5 |
577 |
279 |
|
3.3-3.4 |
279 |
16.8 |
35.7 |
530 |
138 |
|
3.4-3.5 |
501 |
39.9 |
73.2 |
343 |
42.8 |
|
3.5-3.6 |
663 |
71.4 |
115 |
143 |
7.6 |
|
3.6-3.7 |
702 |
105 |
149 |
42.2 |
0.8 |
|
3.7-3.8 |
667 |
142 |
181 |
9.8 |
0.1 |
|
3.8-3.9 |
597 |
185 |
215 |
1.9 |
0 |
|
3.9-4.0 |
510 |
236 |
254 |
0.3 |
0 |
|
4.0-4.1 |
413 |
293 |
294 |
0 |
0 |
|
4.1-4.2 |
316 |
350 |
334 |
0 |
0 |
|
4.2-4.3 |
226 |
404 |
370 |
0 |
0 |
|
4.3-4.4 |
153 |
448 |
400 |
0 |
0 |
|
4.4-4.5 |
97 |
480 |
423 |
0 |
0 |
|
4.5-4.6 |
58.5 |
500 |
441 |
0 |
0 |
|
4.6-4.7 |
33.7 |
510 |
457 |
0 |
0 |
|
4.7-4.8 |
18.6 |
511 |
471 |
0 |
0 |
|
4.8-4.9 |
9.9 |
505 |
485 |
0 |
0 |
|
4.9-5.0 |
5.1 |
494 |
501 |
0 |
0 |
|
5.0-5.1 |
2.5 |
478 |
519 |
0 |
0 |
|
5.1-5.2 |
1.2 |
458 |
540 |
0 |
0 |
|
5.2-5.3 |
0.6 |
435 |
564 |
0 |
0 |
|
5.3-5.4 |
0.3 |
409 |
591 |
0 |
0 |
|
5.4-5.5 |
0.1 |
379 |
621 |
0 |
0 |
|
5.5-5.6 |
0 |
348 |
652 |
0 |
0 |
Nhận xét :
• Rõ ràng, nhìn vào bảng trên chúng ta dễ dàng rút ra rằng các từ ‘Trái’, ‘Phải’,
‘Tới’, ‘Lùi’ sẽ không bao giờ có số mẫu dưới 700, cũng như từ ‘Dừng’ thì không bao giờ có số mẫu vượt quá 900.
• Hai từ ‘Trái’ và ‘Phải’ có phân bố xác suất khá giống nhau, vì vậy 2 từ này rất dễ
gây nhầm lẫn.
Nếu chỉ dựa vào 2 đặc trưng này thì chúng ta vẫn chưa đủ cơ sở để kết luận về từ cần được nhận dạng, vì vậy mà chúng ta cần kết hợp với phương pháp huấn luyện VQ sẽ được trình bày ngay dưới đây.
6.3 Phương pháp huấn luyện VQ
6.3.1 Mở đầu
Sau quá trình phân tích đặc trưng trên, chúng đã có được tập hợp các điểm dữ liệu tạo đại diện cho sự phân bố năng lượng của tín hiệu đầu vào. Vấn đề được đặt ra ở đây là làm sao chúng ta có thể ước lượng đặc trưng để thu được một tập dữ liệu nhỏ, gọn hơn, thuận tiện cho việc nhận dạng tiếng nói. Phương pháp VQ ( vector-quantization ) là một trong những phương pháp hiệu quả để thực hiện việc này.
Trong nhận dạng tiếng nói, phương pháp VQ rất thích hợp với các hệ thống nhận dạng có số từ vựng nhỏ, khoảng 10-20 từ. Phương pháp này chia các không gian lớn thành các vùng vector nhỏ hơn. Mỗi vùng nhỏ được gọi là vùng cụm thông tin (cluster), mỗi cụm thông tin được tính toán trọng tâm, trọng tâm này gọi là codeword. Tập hợp các codeword tạo thành codebook.
Các đặc tính của VQ :
- Giảm thiểu không gian lưu trữ của vector phổ.
- Giảm thời gian tính toán độ giống nhau giữa các vector phổ. Trong nhận dạng tiếng nói, một lượng lớn các phép tính dùng để tính sự giống nhau giữa 2 vector phổ. Dựa vào VQ, việc tính toán được giảm xuống qua việc tìm kiếm sự giống nhau của 2 cặp vector codebook trong bảng tìm kiếm.
- Biểu diễn rời rạc về mặt âm học của tiếng nói. Nhờ việc gán nhãn cho mỗi frame của từng từ, quá trình chọn codebook tốt nhất cho từ đó trong các hệ thống nhận dạng chỉ đơn thuần dựa trên các nhãn này.
Khuyết điểm của VQ :
- Việc lượng tử vector chắc chắn dẫn đến sai số lượng tử hóa. Điều này dẫn đến thông tin phổ bị sai lệch.
- Việc chọn codebook cho VQ không đơn giản. Tăng kích thước sẽ làm giảm sai số lượng tử nhưng lại dẫn đến vấn đề không gian lưu trữ các vector trong codebook. Vì vậy, khi cài đặt VQ, chúng ta phải cân nhắc đến 3 yếu tố : sai số lượng tử, thời gian tìm kiếm vector trong codebook và không gian lưu trữ các vector trong codebook.
6.3.2 Các yếu tố khi tổ chức VQ :sau:
Để xây dựng codebook VQ và tổ chức thuật toán cho VQ, chúng ta cần các yếu tố
- Một tập lớn các vector phổ v1,v2,..,vL là tập huấn luyện cho VQ. Nếu kích thước
codebook của VQ là M=2B (codebook B bit) thì chúng ta cần L>>M để tìm được M
vector tối ưu nhất. Thường chọn L=10M.
- Độ đo d giữa các cặp phổ để phân nhóm vector trong khâu huấn luyện, hay phân lớp vector trong khâu đánh nhãn.
- Phương pháp xác định nhân để phân hoạch L vector thành M nhóm.
- Phương pháp phân lớp các vector ngõ vào. Một vector sau khi phân lớp thì sẽ được đại diện bằng một nhãn (mã).
6.3.3 Tập huấn luyện cho VQ :
Tập huấn luyện cho VQ là tất cả các vector đặc trưng đã qua khâu tách đặc trưng của tất cả các từ. Mỗi vector là 45 hệ số về năng lượng.
6.3.4 Đo độ méo :
Thành phần quan trọng nhất của các thuật toán đối sánh mỗi là độ đo giữa 2 vector đặc trưng. Ở đây chúng ta sử dụng phương pháp hồi quy tuyến tính để xác định hệ số tương quan giữa 2 vector đặc trưng.
Hồi quy tuyến tính là một trong những phương pháp phân tích số liệu thông dụng nhất trong thống kê học. Hệ số tương quan r sẽ cho chúng ta biết sự liên hệ giữa 2 biến số x và y. Hệ số tương quan có giá trị từ -1 đến 1. Hệ số này bằng 0 khi 2 biến số không có liên hệ gì, bằng 1 hay -1 nghĩa là 2 biến số có liên hệ một cách tuyệt đối. Nếu r<0 nghĩa
là khi x tăng thì y giảm và ngược lại. Nếu r>0 nghĩa là khi x tăng thì y tăng, x giảm thì y giảm.
Có nhiều loại hệ số tương quan trong thống kê như : Pearson, Spearman, Kendall…Ở đây, em sử dụng hệ số tương quan Pearson :
là các giá trị trung bình của x và y.
Độ đo này dùng trong khâu phân lớp và gán nhãn cho vector phổ.
6.3.5 Phân nhóm các vector huấn luyện :
Có 2 giải thuật phân nhóm :
a.Giải thuật cụm thông tin ( Cluster Algorithm)
Giải thuật còn được gọi là K-means, Lloyd hay Linde-Buzo-Gray (LBG).
- Khởi tạo: Chọn ngẫu nhiên M vector trong tập huấn luyện L làm tập từ mã
(codeword) ban đầu của codebook.
- Tìm lân cận gần nhất: với mỗi vector huấn luyện v, tìm codeword trong codebook hiện tại có khoảng cách gần nhất đến vector này ( dựa vào độ đo méo) và gán nó thuộc về cell của codeword đó.
DANH MỤC HÌNH VẼ
Hình 1.1 Tổng quát về hệ thống……………………………….…………………... 2
Hình 1.2 Hệ thống nhận dạng tiếng nói……………………….…………………… 3
Hình 1.3 Quá trình tách từ…………………………………….…………………… 4
Hình 1.4 Quá trình lấy đặc trưng……………………………….………………….. 4
Hình 1.5 Quá trình nhận dạng………………………………….………………….. 5
Hình 2.1 Bộ máy phát âm…………………………………………………………...8
Hình 2.2 Cấu trúc khoang miệng…………………………………………………. 9
Hình 2.3 Dây thanh và thanh môn………………………………………………… 10
Hình 2.4 Hình dạng thanh môn ở các vị trí…………………………………………10
Hình 2.5 Sơ đồ khối bộ máy phát âm………………………………………….…. 11
Hình 2.6 Dây thanh trong một chu kỳ dao động………………………………….. 12
Hình 2.7 Biểu diễn tín hiệu âm thanh dưới dạng sóng……………………………. 12
Hình 2.8 Dạng sóng được thu từ 2 mic khác nhau………………………………… 13
Hình 2.9 Hai giọng nói khác nhau cho cùng một âm……………………………… 13
Hình 2.10 Cùng 1 âm do cùng 1 người nói………………………………………... 14
Hình 2.11 Tiếng nói và phổ tiếng nói (1)………………………………………….. 14
Hình 2.12 Tiếng nói và phổ tiếng nói (2)…………………………………………. 15
Hình 2.13 Sonagram……………………………………………………………...... 15
Hình 2.14 Frame tín hiệu tiếng nói………………………………………………... 16
Hình 2.15 Đường bao phổ và các formant……………………………………….... 17
Hình 3.1 Bộ lọc Sallen-Key tổng quát……………………………………………. 20
Hình 3.2 Standard condenser micro (a) và electret condenser micro (b)………….. 20
Hình 3.3. Mạch phân cực cho microphone………………………………………… 21
Hình 3.4 Hình dạng của electret condenser………………………………………. 22
Hình 3.5.Chân của electret condenser………………………………………………22
Hình 3.5. Sơ đồ chân của OP07……………………………………………………. 23
Hình 3.6. Mạch chỉnh offset cho OP07……………………………………………..24
Hình 3.7 Mạch khuếch đại và lọc thông cao…………………………………......... 25
Hình 3.8. Mạch lọc thông cao………………………………………...………........ 26
Hình 3.9. Bộ lọc thông thấp thụ động bậc nhất……………………....……………. 27
Hình 3.10.Mạch lọc thông thấp Sallen-Key……………………………..……........ 28
Hình 3.11 Mạch lọc-đệm Sallen-Key…………………………………………........ 29
Hình 3.12 Mạch lọc thông thấp bậc 6……………………………………………… 29
Hình 3.13 Mạch cộng điện áp dùng OPAMP……………………………………… 30
Hình 3.14 Mạch dịch mức điện áp………………………………………………… 31
Hình 3.15 Mạch khuếch đại, tiền lọc hoàn chỉnh………………………………….. 31
Hình 3.16 Đáp ứng xung của một bộ lọc FIR…………………………………….... 33
Hình 3.17 Đáp ứng xung của một bộ lọc IIR……………………………………… 34
Hình 3.18 Các loại bộ lọc IIR……………………………………………………… 35
Hình 3.19 Đáp ứng biên độ của bộ lọc Chebyshev 2……………………………… 36
Hình 3.20 Đáp ứng pha của bộ lọc Chebyshev 2 …………………………………..36
Hình 3.21 Bộ lọc IIR dạng trực tiếp……………………………………………….. 37
Hình 3.22 Bộ lọc IIR dạng canonical……………………………………………….37
Hình 3.23 Sử dụng công cụ SPTool (1)………………………………………......... 39
Hình 3.24 Sử dụng công cụ SPTool (2)…………………………………………… 40
Hình 3.25 Sử dụng công cụ SPTool (3)……………………………………………. 41
Hình 3.26 Sử dụng công cụ SPTool (4)……………………………………………. 42
Hình 3.26 Sử dụng công cụ SPTool (5)……………………………………………. 43
Hình 3.27 Tín hiệu ‘phải’ trước khi qua bộ lọc……………………………………. 44
Hình 3.28 Tín hiệu ‘phải’ sau khi qua một bộ lọc…………………………………. 44
Hình 3.29 Phổ công suất từ Hello…………………………………………………. 45
Hình 3.30 Phổ công suất từ Right…………………………………………………. 46
Hình 4.1 Các dòng cơ bản của AVR………………………………………………. 48
Hình 4.2 Cấu trúc của vi điều khiển AVR…………………………………………. 49
Hình 4.3 Sơ đồ chân của ATmega32………………………………………………. 50
Hình 4.4 Bộ nhớ chương trình……………………………………………………... 51
Hình 4.5 Bộ nhớ chương trình khi sử dụng bootloader hoặc không………………. 52
Hình 4.6 Bộ nhớ SRAM…………………………………………………………… 53
Hình 4.7 Truy xuất bộ nhớ SRAM………………………………………………… 53
Hình 4.8 Sơ đồ một cổng vào ra…………………………………………………… 55
Hình 4.9 Sơ đồ khối của Timer 0………………………………………………….. 56
Hình 4.10 Sơ đồ khối bộ ADC…………………………………………………….. 59
Hình 4.11 Ngõ vào vi sai………………………………………………………….. 63
Hình 4.12 Kết nối LCD với AVR (1)……………………………………………… 64
Hình 4.13 Kết nối LCD với AVR (2)……………………………………………… 65
Hình 4.14 Mạch nạp AVR (1)………………………………………………………66
Hình 4.14 Mạch nạp AVR (2)………………………………………………………66
Hình 4.16 Kết nối mạch nạp với AVR…………………………………………….. 67
Hình 4.17 Phần mềm CodeVisionAVR…………………………………………… 68
Hình 4.18 Các module được hỗ trợ của CodeVisionAVR………………………….69
Hình 4.19 Thiết lập thông số mạch nạp……………………………………………. 69
Hình 4.20 Bộ nạp của CodeVisionAVR…………………………………………… 70
Hình 5.1 Các vùng của tiếng nói……………………………………………………73
Hình 5.2 Quá trình tách từ…………………………………………………………. 74
Hình 5.3 Chia frame………………………………………………………………. 74
Hình 5.4 Ngưỡng nhiễu……………………………………………………………. 75
Hình 5.5 Tiếng nói sau khi lọc bỏ nhiễu…………………………………………… 77
Hình 5.6 Đường bao phổ và các Formant…………………………………………. 78
Hình 5.7 Các Formant của âm A………………………………………………….. 78
Hình 6.1 Hàm mật độ xác suất…………………………………………………….. 84
Hình 6.2 Sơ đồ cấu trúc VQ huấn luyện và phân lớp……………………………… 89
Hình 6.3 Lưu đồ giải thuật LGB…………………………………………………… 90
Hình 6.4 Lưu đồ giải thuật Binary Split…………………………………………… 94
Hình 6.5 Quá trình nhận dạng………………………………………………………95
Hình 7.1 Sơ đồ mạch điều khiển……………………………………………………97
Hình 7.2 Mạch điều khiển…………………………………………………………. 98
Hình 7.3 Mạch nguồn……………………………………………………………… 98
Hình 7.3 Mạch cầu H……………………………………………………………… 99
Hình 7.4 IC TA7291P……………………………………………………………… 99